




Ce que Google est en train de changer discrètement
Un de nos clients nous a appelé récemment, agacé. Son site recevait des milliers de visites “fantômes” dans Google Analytics — des bots qui faussaient ses données, polluaient ses stats de conversion, rendaient ses décisions marketing inutilisables. Problème classique. Solution actuelle : approximative.
Parce qu’aujourd’hui, identifier un bot légitime d’un imposteur, c’est largement une question de confiance aveugle. Google déclare être Google. Vous lui faites confiance — ou pas. Et si quelqu’un usurpe l’identité du Googlebot pour scraper votre contenu ? Vous n’avez quasiment aucun moyen de le prouver en temps réel.
C’est exactement ce problème que Google cherche à résoudre avec Web Bot Auth, un protocole cryptographique expérimental qui pourrait changer les règles du jeu pour le SEO technique, la gestion des crawlers et la fiabilité de vos données.
Voici ce que ça signifie concrètement pour votre site — et pour votre stratégie de référencement naturel sur le long terme.
Le problème que personne ne résolvait vraiment
Le robots.txt existe depuis 1994. Trente ans. C’est le même mécanisme de base : vous posez un fichier texte à la racine de votre site, vous listez ce que les robots peuvent ou ne peuvent pas crawler. Simple. Efficace pour les bots qui respectent les règles.
Mais voilà le piège classique : un bot malveillant ne lit pas votre robots.txt. Ou plutôt, il le lit, l’ignore, et continue. Et un bot qui se fait passer pour Googlebot ? Votre serveur lui ouvre la porte sans sourciller.
La méthode de vérification actuelle recommandée par Google elle-même repose sur une résolution DNS inverse. Concrètement : vous prenez l’adresse IP du crawler, vous faites une résolution DNS inverse pour vérifier qu’elle appartient bien à Google, puis une résolution DNS directe pour confirmer. Ça marche. Mais c’est manuel, chronophage, et totalement inadapté à une vérification en temps réel à grande échelle.
Résultat sur le terrain ? La plupart des hébergeurs et des systèmes de cache font confiance au User-Agent déclaré. Ce qui signifie que n’importe qui peut se déclarer Googlebot et bénéficier des règles d’exception que vous avez configurées pour les crawlers légitimes. C’est le prolongement direct de ce qu’on décrivait dans robots.txt, Google Search Console et fiches produits : la nouvelle ère du SEO technique — la couche déclarative ne suffit plus.
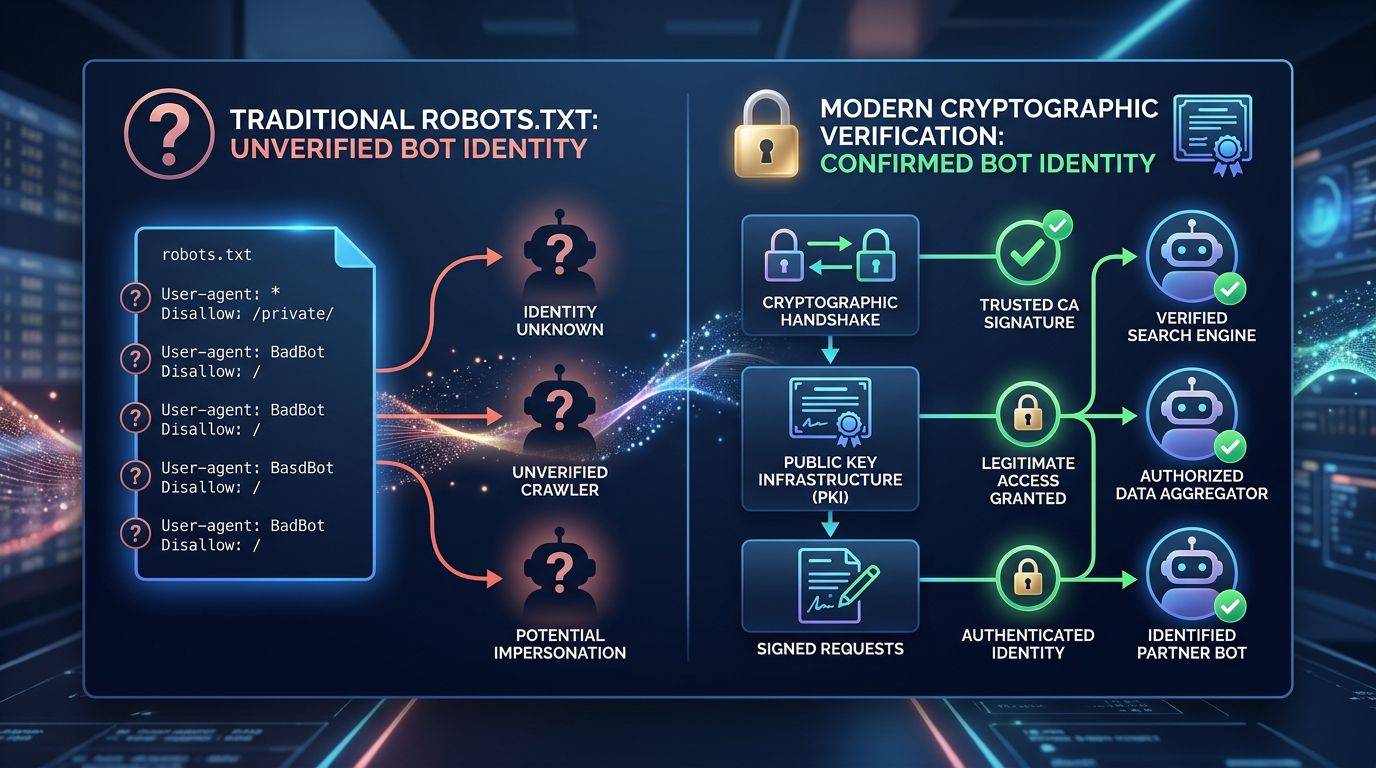
Web Bot Auth : le principe cryptographique expliqué simplement
L’idée derrière Web Bot Auth est empruntée à un principe bien connu en sécurité informatique : la signature cryptographique.
Quand le Googlebot visite votre site, il présente une signature numérique générée avec une clé privée que seul Google possède. Votre serveur peut vérifier cette signature en utilisant la clé publique correspondante — disponible et vérifiable par n’importe qui. Si la signature est valide, c’est bien Google. Si elle ne l’est pas, c’est un imposteur.
C’est le même principe que les certificats SSL/TLS qui sécurisent les connexions HTTPS. Vous faites confiance à un certificat parce qu’il a été signé par une autorité reconnue, pas parce que le site vous dit qu’il est sécurisé.
Voici ce que ça change dans la pratique :
La vérification devient instantanée
Plus besoin de résolution DNS inverse laborieuse. La signature est vérifiable en quelques millisecondes, directement au niveau serveur ou CDN. Ce qui était une opération manuelle post-crawl devient une vérification en temps réel.
L’usurpation d’identité devient (quasi) impossible
Sans la clé privée de Google, impossible de générer une signature valide. Un scraper qui se déclare Googlebot sera immédiatement identifié comme imposteur — et vous pourrez le bloquer, le logger, ou lui servir un contenu différent.
Chaque moteur peut avoir sa propre identité vérifiable
Web Bot Auth n’est pas exclusif à Google. Le protocole est conçu pour être adopté par Bing, Yandex, ou n’importe quel crawler légitime. Un standard ouvert, pas un outil propriétaire.
Ce que ça change pour votre SEO technique
Soyons directs : Web Bot Auth est encore expérimental. Google teste, documente, itère. Ce n’est pas déployé à grande échelle aujourd’hui. Mais ignorer cette évolution parce qu’elle n’est pas encore en production, c’est exactement l’erreur que font les équipes qui courent toujours après les mises à jour au lieu de les anticiper.
Voici où ça devient intéressant pour votre stratégie.
La gestion du budget de crawl va devenir plus fine
Le crawl budget — la quantité de pages que Googlebot accepte de crawler sur votre site dans un temps donné — est une ressource limitée, particulièrement critique pour les sites e-commerce avec des milliers de références ou les sites à fort volume de contenu.
Avec Web Bot Auth, vous pourrez distinguer avec certitude les crawls légitimes des crawls parasites. Résultat : vos logs serveur deviennent exploitables. Vous pouvez mesurer précisément ce que Google crawle réellement, identifier les pages ignorées, et optimiser votre architecture en conséquence.
Aujourd’hui, beaucoup d’analyses de logs sont polluées par des bots non identifiés qui se font passer pour des crawlers légitimes. Vos décisions d’architecture SEO reposent sur des données partiellement faussées. Vous ne le savez pas forcément — mais c’est le cas.
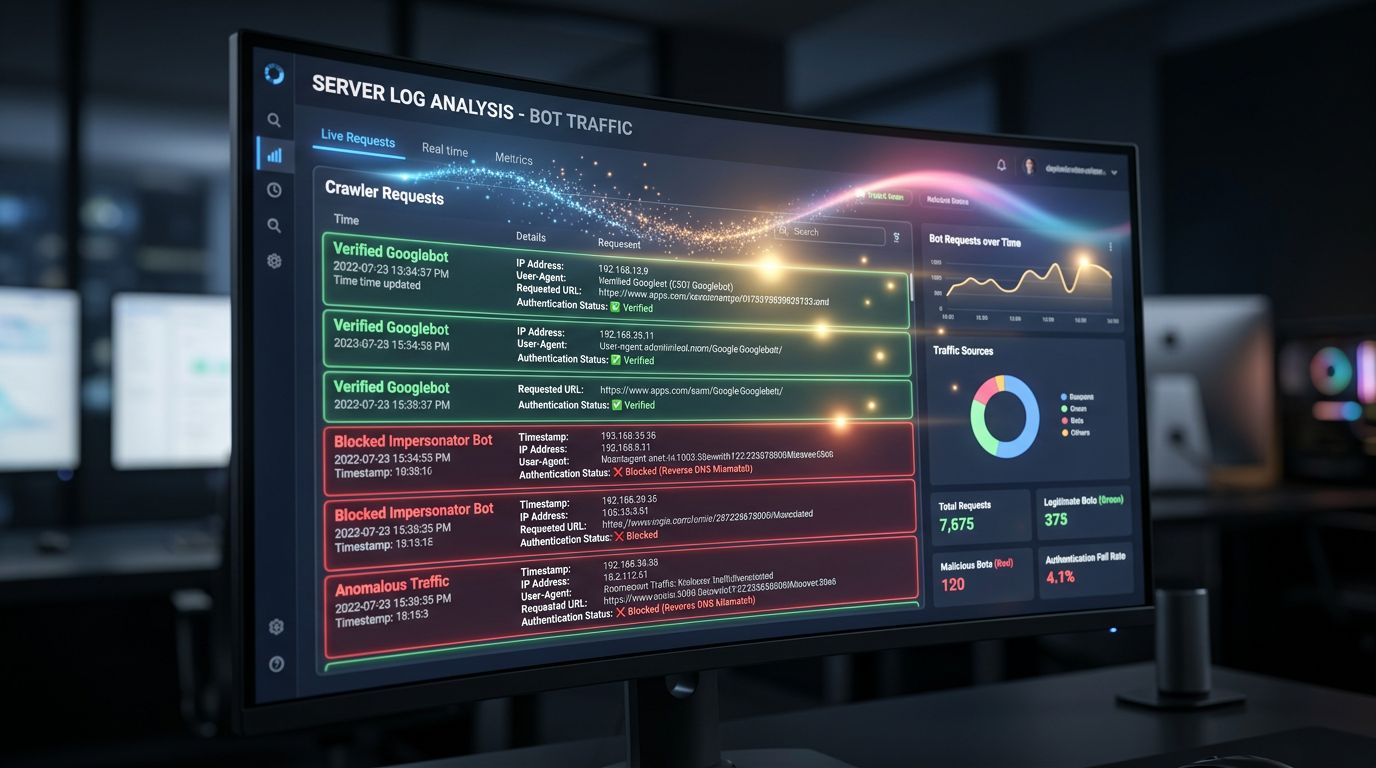
La qualité de vos données analytics va s’améliorer
Ce client dont je parlais en introduction — ses données faussées par des bots — c’est un problème que Web Bot Auth attaque directement. Quand vous pouvez identifier avec certitude les requêtes de crawlers légitimes, vous pouvez les exclure proprement de vos analyses de trafic.
Aujourd’hui, les filtres anti-bots dans Google Analytics ou dans vos outils de web analytics reposent sur des listes noires, des seuils comportementaux, des heuristiques. C’est imparfait. Une vérification cryptographique, c’est binaire : légitime ou non. Vos taux de rebond, vos conversions, vos données de session — tout devient plus fiable.
Les règles de cache et de CDN vont évoluer
Beaucoup de configurations CDN (Cloudflare, Fastly, Akamai) appliquent des règles spécifiques aux crawlers connus : pas de cache, contenu complet, pas de challenge JavaScript. Ces règles reposent actuellement sur des listes d’IP et des User-Agents — vérifiables, mais contournables.
Avec Web Bot Auth intégré au niveau CDN, ces règles pourront s’appliquer sur la base d’une vérification cryptographique réelle. Plus robuste. Plus fiable. Et potentiellement, plus de flexibilité pour servir du contenu différencié selon que le visiteur est un humain, un crawler légitime, ou un bot non identifié.
Ce que ça ne résout pas (soyons honnêtes)
Web Bot Auth est une avancée réelle. Mais ce n’est pas une solution miracle — et promettre le contraire, ce n’est pas mon style.
Le problème du contenu dupliqué ne disparaît pas. L’authentification des bots ne change rien à la façon dont Google évalue la qualité de votre contenu, gère les balises canoniques, ou traite les versions dupliquées de vos pages. C’est un problème d’architecture SEO, pas d’identification de crawlers.
Les bots malveillants vont s’adapter. L’authentification cryptographique bloque l’usurpation d’identité des crawlers légitimes. Mais les scrapers qui ne prétendent pas être Googlebot — ceux qui se déclarent simplement comme un navigateur ordinaire — continuent exactement comme avant. Web Bot Auth ne résout pas le scraping en général.
L’adoption prendra du temps. Pour que ce protocole soit utile, il faut que les serveurs web, les CDN, les WAF et les outils d’analyse l’intègrent. On parle d’un écosystème entier à faire évoluer. Dans les faits, avec nos clients, on voit que même des standards bien établis mettent des années à être correctement implémentés.
“La sécurité parfaite n’existe pas. Mais chaque couche supplémentaire de vérification rend l’attaque exponentiellement plus coûteuse pour l’attaquant.” — principe fondamental en sécurité informatique
Ce que vous devriez faire maintenant, concrètement
Web Bot Auth n’est pas encore déployé. Vous n’avez pas d’action immédiate à prendre sur ce protocole spécifique. Mais cette évolution devrait vous inciter à auditer votre stack technique dès maintenant — parce que les fondations que vous posez aujourd’hui déterminent votre capacité à intégrer ces changements demain.
Commencez par analyser vos logs serveur. Si vous ne regardez pas vos logs de crawl régulièrement, vous pilotez à l’aveugle. Outils recommandés : Screaming Frog Log File Analyser, ou un setup ELK stack si vous avez le volume. Identifiez ce qui crawle votre site, à quelle fréquence, sur quelles pages.
Vérifiez votre configuration robots.txt et votre crawl budget. Bloquez-vous les ressources que vous devriez bloquer ? Autorisez-vous le crawl des pages à faible valeur (filtres, paramètres URL, pages de pagination inutiles) ? Un audit honnête de votre robots.txt révèle souvent des années de configurations obsolètes empilées.
Préparez votre infrastructure à l’authentification au niveau serveur. Si vous utilisez Nginx ou Apache, familiarisez-vous avec les modules de vérification de requêtes — et assurez-vous d’avoir lu notre guide pour comprendre les en-têtes HTTP et leur impact sur le SEO, parce que c’est exactement à ce niveau que les signatures Web Bot Auth se vérifieront. Quand le protocole sera disponible, l’implémentation sera d’autant plus rapide que votre équipe technique comprend le principe.
Nettoyez vos données analytics maintenant. Mettez en place des filtres bot robustes dans Google Analytics 4, activez le filtrage des bots connus, et si vous avez un volume significatif, envisagez un outil d’analyse côté serveur (Matomo, Plausible) moins dépendant du JavaScript pour la collecte.

Trois points à retenir
1. La confiance aveugle dans les User-Agents est une faille structurelle. Web Bot Auth n’est pas une amélioration marginale — c’est une refonte du principe de confiance qui gouverne les interactions entre votre site et les crawlers depuis 30 ans.
2. Vos données de crawl sont probablement moins fiables que vous ne le pensez. Avant même que Web Bot Auth soit disponible, analyser vos logs et nettoyer vos données analytics vous donnera une vision plus juste de ce que Google crawle réellement sur votre site.
3. Le SEO technique s’industrialise. L’authentification cryptographique des bots, les Core Web Vitals, le budget de crawl — ces sujets ne sont plus réservés aux équipes de grands groupes. Une PME avec un site de 50 pages doit comprendre ces mécanismes pour ne pas laisser ses concurrents prendre de l’avance.
La prochaine étape pour votre site
Après 15 ans à construire et optimiser des sites pour des entreprises normandes et françaises, un constat s’impose : les PME qui prennent de l’avance sur les évolutions techniques ne sont pas celles qui ont les plus gros budgets. Ce sont celles qui font auditer leur infrastructure régulièrement, avant que les problèmes deviennent visibles dans leurs résultats.
Web Bot Auth va changer la façon dont les crawlers interagissent avec votre site. La question n’est pas si vous devez vous y préparer — c’est quand.
Si vous voulez qu’on audite votre configuration technique actuelle — logs de crawl, robots.txt, budget de crawl, filtrage des bots dans vos analytics — c’est exactement le type d’intervention qu’on mène chez GDM-Pixel. Diagnostic honnête, recommandations actionnables, pas de refonte vendue quand un audit de deux jours suffit.
Prenez contact avec notre équipe — on regarde ce que vos données disent vraiment de votre visibilité Google.






