




Lo que Google está cambiando discretamente
Uno de nuestros clientes nos llamó recientemente, molesto. Su sitio recibía miles de visitas “fantasma” en Google Analytics — bots que distorsionaban sus datos, contaminaban sus estadísticas de conversión y hacían inutilizables sus decisiones de marketing. Problema clásico. Solución actual: aproximada.
Porque hoy en día, identificar un bot legítimo de un impostor es en gran medida una cuestión de confianza ciega. Google declara ser Google. Usted confía en él — o no. ¿Y si alguien suplanta la identidad del Googlebot para raspar su contenido? Prácticamente no tiene forma de probarlo en tiempo real.
Es exactamente este problema el que Google busca resolver con Web Bot Auth, un protocolo criptográfico experimental que podría cambiar las reglas del juego para el SEO técnico, la gestión de crawlers y la fiabilidad de sus datos.
Esto es lo que significa concretamente para su sitio — y para su estrategia de posicionamiento SEO a largo plazo.
El problema que nadie resolvía de verdad
El robots.txt existe desde 1994. Treinta años. Es el mismo mecanismo básico: coloca un archivo de texto en la raíz de su sitio y lista lo que los robots pueden o no pueden rastrear. Simple. Efectivo para los bots que respetan las reglas.
Pero aquí está la trampa clásica: un bot malicioso no lee su robots.txt. O mejor dicho, lo lee, lo ignora y continúa. ¿Y un bot que se hace pasar por Googlebot? Su servidor le abre la puerta sin pestañear.
El método de verificación actual recomendado por el propio Google se basa en una resolución DNS inversa. Concretamente: toma la dirección IP del crawler, realiza una resolución DNS inversa para verificar que pertenece a Google, luego una resolución DNS directa para confirmar. Funciona. Pero es manual, lleva mucho tiempo y es totalmente inadecuado para una verificación en tiempo real a gran escala.
¿El resultado en la práctica? La mayoría de los servidores de alojamiento y sistemas de caché confían en el User-Agent declarado. Lo que significa que cualquiera puede declararse Googlebot y beneficiarse de las reglas de excepción que configuró para los crawlers legítimos. Es la extensión directa de lo que describíamos en robots.txt, Google Search Console y fichas de producto: la nueva era del SEO técnico — la capa declarativa ya no es suficiente.
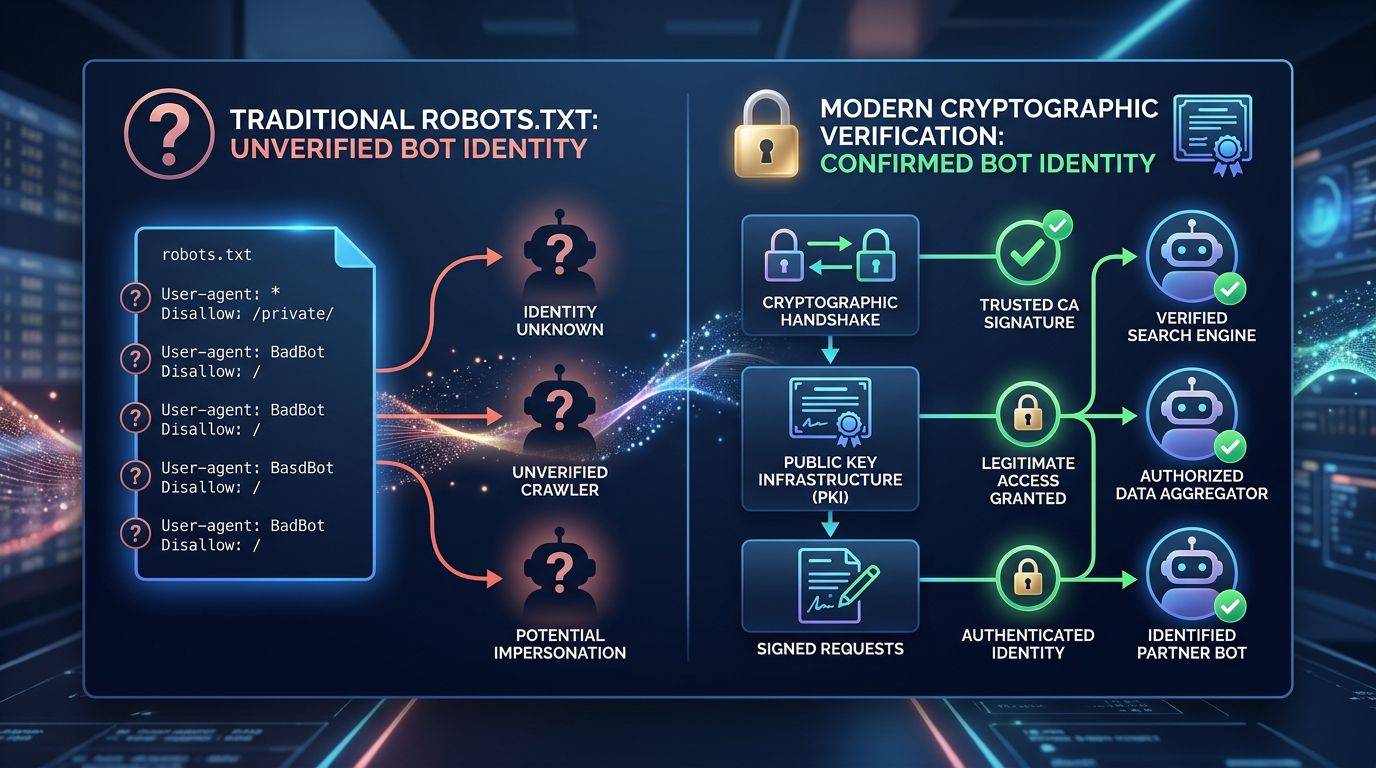
Web Bot Auth: el principio criptográfico explicado simplemente
La idea detrás de Web Bot Auth está tomada de un principio bien conocido en seguridad informática: la firma criptográfica.
Cuando el Googlebot visita su sitio, presenta una firma digital generada con una clave privada que solo Google posee. Su servidor puede verificar esta firma usando la clave pública correspondiente — disponible y verificable por cualquiera. Si la firma es válida, es Google. Si no lo es, es un impostor.
Es el mismo principio que los certificados SSL/TLS que protegen las conexiones HTTPS. Confía en un certificado porque fue firmado por una autoridad reconocida, no porque el sitio le diga que es seguro.
Esto es lo que cambia en la práctica:
La verificación se vuelve instantánea
No más laborioso proceso de resolución DNS inversa. La firma es verificable en unos pocos milisegundos, directamente al nivel del servidor o CDN. Lo que era una operación manual posterior al rastreo se convierte en una verificación en tiempo real.
La suplantación de identidad se vuelve (casi) imposible
Sin la clave privada de Google, es imposible generar una firma válida. Un scraper que se declare Googlebot será identificado inmediatamente como impostor — y podrá bloquearlo, registrarlo o servirle un contenido diferente.
Cada motor puede tener su propia identidad verificable
Web Bot Auth no es exclusivo de Google. El protocolo está diseñado para ser adoptado por Bing, Yandex o cualquier crawler legítimo. Un estándar abierto, no una herramienta propietaria.
Lo que esto cambia para su SEO técnico
Seamos directos: Web Bot Auth sigue siendo experimental. Google prueba, documenta, itera. No está desplegado a gran escala hoy. Pero ignorar esta evolución porque todavía no está en producción es exactamente el error que cometen los equipos que siempre van detrás de las actualizaciones en lugar de anticiparlas.
Aquí es donde se vuelve interesante para su estrategia.
La gestión del presupuesto de rastreo se volverá más precisa
El presupuesto de rastreo — la cantidad de páginas que el Googlebot acepta rastrear en su sitio en un tiempo dado — es un recurso limitado, especialmente crítico para los sitios de comercio electrónico con miles de referencias o los sitios con gran volumen de contenido.
Con Web Bot Auth, podrá distinguir con certeza los rastreos legítimos de los parásitos. Resultado: sus registros del servidor se vuelven utilizables. Puede medir con precisión lo que Google rastrea realmente, identificar las páginas ignoradas y optimizar su arquitectura en consecuencia.
Hoy en día, muchos análisis de registros están contaminados por bots no identificados que se hacen pasar por crawlers legítimos. Sus decisiones de arquitectura SEO se basan en datos parcialmente distorsionados. Puede que no lo sepa — pero así es.
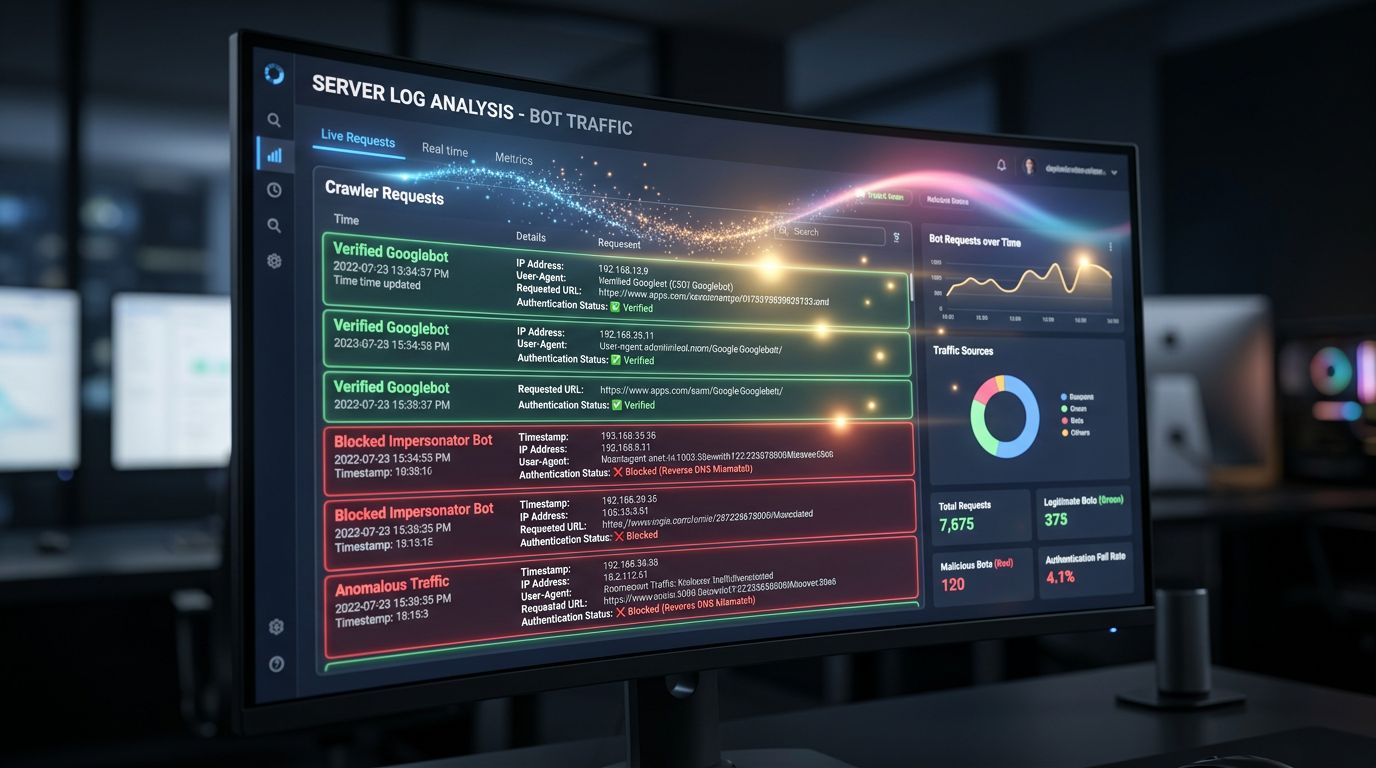
La calidad de sus datos analíticos mejorará
Ese cliente del que hablaba en la introducción — sus datos distorsionados por bots — es un problema que Web Bot Auth ataca directamente. Cuando puede identificar con certeza las solicitudes de crawlers legítimos, puede excluirlos correctamente de sus análisis de tráfico.
Hoy en día, los filtros anti-bots en Google Analytics o en sus herramientas de análisis web se basan en listas negras, umbrales de comportamiento y heurísticas. Es imperfecto. Una verificación criptográfica es binaria: legítimo o no. Sus tasas de rebote, conversiones y datos de sesión — todo se vuelve más fiable.
Las reglas de caché y CDN evolucionarán
Muchas configuraciones de CDN (Cloudflare, Fastly, Akamai) aplican reglas específicas a los crawlers conocidos: sin caché, contenido completo, sin desafío JavaScript. Estas reglas actualmente se basan en listas de IP y User-Agents — verificables pero evitables.
Con Web Bot Auth integrado a nivel de CDN, estas reglas podrán aplicarse sobre la base de una verificación criptográfica real. Más robusta. Más fiable. Y potencialmente, más flexibilidad para servir contenido diferenciado según si el visitante es un humano, un crawler legítimo o un bot no identificado.
Lo que no resuelve (seamos honestos)
Web Bot Auth es un avance real. Pero no es una solución milagrosa — y prometer lo contrario no es mi estilo.
El problema del contenido duplicado no desaparece. La autenticación de bots no cambia nada en la forma en que Google evalúa la calidad de su contenido, gestiona las etiquetas canónicas o trata las versiones duplicadas de sus páginas. Es un problema de arquitectura SEO, no de identificación de crawlers.
Los bots maliciosos se adaptarán. La autenticación criptográfica bloquea la suplantación de identidad de los crawlers legítimos. Pero los scrapers que no pretenden ser Googlebot — los que simplemente se declaran como un navegador ordinario — continúan exactamente como antes. Web Bot Auth no resuelve el scraping en general.
La adopción llevará tiempo. Para que este protocolo sea útil, los servidores web, los CDN, los WAF y las herramientas de análisis deben integrarlo. Estamos hablando de todo un ecosistema que debe evolucionar. En la práctica, con nuestros clientes, vemos que incluso los estándares bien establecidos tardan años en implementarse correctamente.
“La seguridad perfecta no existe. Pero cada capa adicional de verificación hace que el ataque sea exponencialmente más costoso para el atacante.” — principio fundamental en seguridad informática
Lo que debería hacer ahora, concretamente
Web Bot Auth aún no está desplegado. No tiene ninguna acción inmediata que tomar sobre este protocolo específico. Pero esta evolución debería incitarle a auditar su pila técnica ahora mismo — porque los fundamentos que establece hoy determinan su capacidad para integrar estos cambios mañana.
Comience analizando sus registros del servidor. Si no revisa regularmente sus registros de rastreo, está operando a ciegas. Herramientas recomendadas: Screaming Frog Log File Analyser, o una configuración de pila ELK si tiene el volumen. Identifique qué está rastreando su sitio, con qué frecuencia y en qué páginas.
Verifique su configuración de robots.txt y su presupuesto de rastreo. ¿Está bloqueando los recursos que debería bloquear? ¿Está permitiendo el rastreo de páginas de bajo valor (filtros, parámetros de URL, páginas de paginación inútiles)? Una auditoría honesta de su robots.txt revela con frecuencia años de configuraciones obsoletas acumuladas.
Prepare su infraestructura para la autenticación a nivel de servidor. Si usa Nginx o Apache, familiarícese con los módulos de verificación de solicitudes — y asegúrese de haber leído nuestra guía para comprender las cabeceras HTTP y su impacto en el SEO, porque es exactamente a ese nivel donde se verificarán las firmas de Web Bot Auth. Cuando el protocolo esté disponible, la implementación será tanto más rápida cuanto mejor comprenda el principio su equipo técnico.
Limpie sus datos analíticos ahora. Configure filtros de bots robustos en Google Analytics 4, active el filtrado de bots conocidos y, si tiene un volumen significativo, considere una herramienta de análisis del lado del servidor (Matomo, Plausible) menos dependiente de JavaScript para la recopilación de datos.

Tres puntos a recordar
1. La confianza ciega en los User-Agents es una falla estructural. Web Bot Auth no es una mejora marginal — es una reformulación del principio de confianza que ha gobernado las interacciones entre su sitio y los crawlers durante 30 años.
2. Sus datos de rastreo probablemente son menos fiables de lo que piensa. Incluso antes de que Web Bot Auth esté disponible, analizar sus registros y limpiar sus datos analíticos le dará una visión más precisa de lo que Google rastrea realmente en su sitio.
3. El SEO técnico se industrializa. La autenticación criptográfica de bots, los Core Web Vitals, el presupuesto de rastreo — estos temas ya no están reservados para los equipos de grandes empresas. Una pyme con un sitio de 50 páginas debe comprender estos mecanismos para no dejar que sus competidores tomen ventaja.
El próximo paso para su sitio
Después de 15 años construyendo y optimizando sitios para empresas en Normandía y en Francia, una constatación es inevitable: las pymes que se adelantan a las evoluciones técnicas no son las que tienen los mayores presupuestos. Son las que hacen auditar su infraestructura regularmente, antes de que los problemas se vuelvan visibles en sus resultados.
Web Bot Auth cambiará la forma en que los crawlers interactúan con su sitio. La pregunta no es si debe prepararse — es cuándo.
Si quiere que auditemos su configuración técnica actual — registros de rastreo, robots.txt, presupuesto de rastreo, filtrado de bots en sus análisis — es exactamente el tipo de intervención que realizamos en GDM-Pixel. Diagnóstico honesto, recomendaciones accionables, sin reforma vendida cuando una auditoría de dos días es suficiente.
Contacte con nuestro equipo — veremos lo que sus datos dicen realmente sobre su visibilidad en Google.






