




What Google is quietly changing
One of our clients called us recently, frustrated. Their site was receiving thousands of “ghost” visits in Google Analytics — bots distorting their data, polluting their conversion stats, making their marketing decisions unusable. A classic problem. Current solution: approximate.
Because today, identifying a legitimate bot from an impostor is largely a matter of blind trust. Google declares it is Google. You trust it — or you don’t. And if someone impersonates Googlebot to scrape your content? You have virtually no way to prove it in real time.
This is exactly the problem Google is trying to solve with Web Bot Auth, an experimental cryptographic protocol that could change the rules of the game for technical SEO, crawler management, and the reliability of your data.
Here is what it means concretely for your site — and for your long-term SEO strategy.
The problem nobody was really solving
robots.txt has existed since 1994. Thirty years. It is the same basic mechanism: you place a text file at the root of your site, you list what robots can or cannot crawl. Simple. Effective for bots that follow the rules.
But here is the classic trap: a malicious bot does not read your robots.txt. Or rather, it reads it, ignores it, and continues. And a bot impersonating Googlebot? Your server opens the door without flinching.
The current verification method recommended by Google itself relies on reverse DNS resolution. In practice: you take the crawler’s IP address, perform a reverse DNS lookup to verify it belongs to Google, then a forward DNS lookup to confirm. It works. But it is manual, time-consuming, and completely unsuited to real-time verification at scale.
The result in practice? Most hosting providers and cache systems trust the declared User-Agent. This means anyone can declare themselves Googlebot and benefit from the exception rules you configured for legitimate crawlers. It is the direct extension of what we described in robots.txt, Google Search Console and product pages: the new era of technical SEO — the declarative layer is no longer enough.
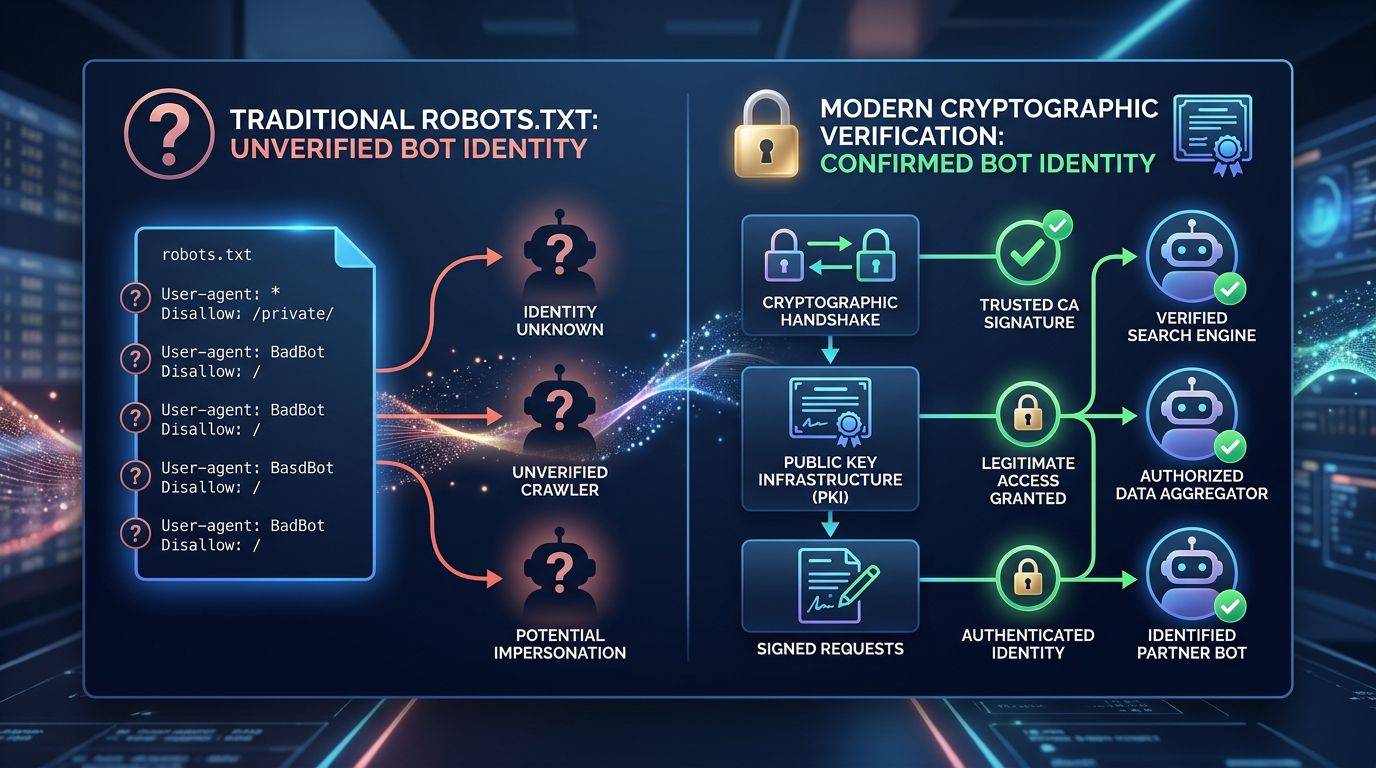
Web Bot Auth: the cryptographic principle explained simply
The idea behind Web Bot Auth is borrowed from a well-known principle in computer security: cryptographic signing.
When Googlebot visits your site, it presents a digital signature generated with a private key only Google holds. Your server can verify this signature using the corresponding public key — available and verifiable by anyone. If the signature is valid, it is indeed Google. If it is not, it is an impostor.
This is the same principle as SSL/TLS certificates that secure HTTPS connections. You trust a certificate because it was signed by a recognised authority, not because the site tells you it is secure.
Here is what it changes in practice:
Verification becomes instantaneous
No more laborious reverse DNS resolution. The signature is verifiable in a few milliseconds, directly at the server or CDN level. What was a manual post-crawl operation becomes a real-time verification.
Identity theft becomes (nearly) impossible
Without Google’s private key, it is impossible to generate a valid signature. A scraper declaring itself Googlebot will be immediately identified as an impostor — and you can block it, log it, or serve it different content.
Each search engine can have its own verifiable identity
Web Bot Auth is not exclusive to Google. The protocol is designed to be adopted by Bing, Yandex, or any legitimate crawler. An open standard, not a proprietary tool.
What this changes for your technical SEO
Let us be direct: Web Bot Auth is still experimental. Google is testing, documenting, iterating. It is not deployed at scale today. But ignoring this evolution because it is not yet in production is exactly the mistake made by teams that are always chasing updates instead of anticipating them.
Here is where it becomes interesting for your strategy.
Crawl budget management will become more precise
The crawl budget — the number of pages Googlebot agrees to crawl on your site within a given time — is a limited resource, particularly critical for e-commerce sites with thousands of products or high-volume content sites.
With Web Bot Auth, you will be able to distinguish with certainty legitimate crawls from parasitic ones. Result: your server logs become usable. You can accurately measure what Google is really crawling, identify ignored pages, and optimise your architecture accordingly.
Today, many log analyses are polluted by unidentified bots posing as legitimate crawlers. Your SEO architecture decisions rest on partially distorted data. You may not know it — but that is the case.
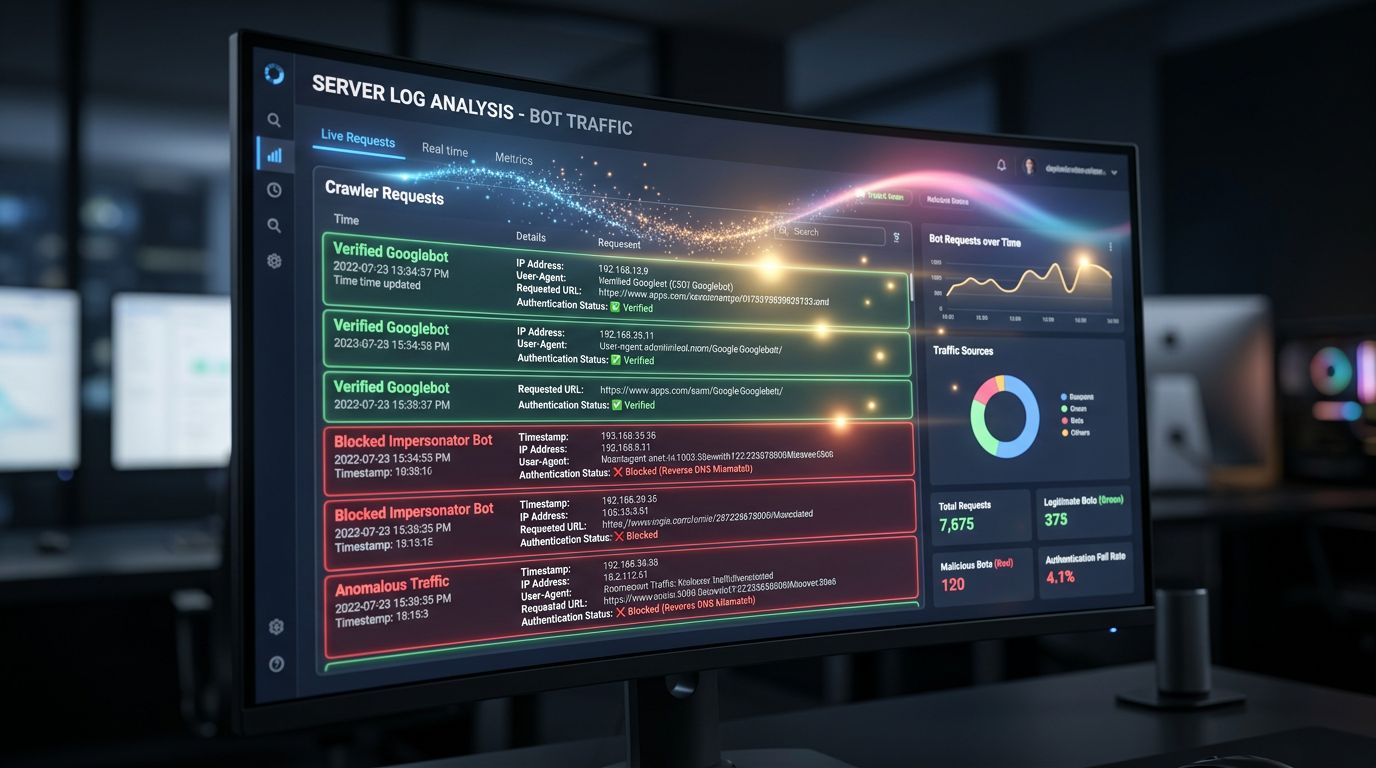
The quality of your analytics data will improve
That client I mentioned in the introduction — their data distorted by bots — is a problem Web Bot Auth addresses directly. When you can identify with certainty the requests from legitimate crawlers, you can properly exclude them from your traffic analyses.
Today, anti-bot filters in Google Analytics or your web analytics tools rely on blacklists, behavioural thresholds, heuristics. It is imperfect. A cryptographic verification is binary: legitimate or not. Your bounce rates, conversions, session data — everything becomes more reliable.
Cache and CDN rules will evolve
Many CDN configurations (Cloudflare, Fastly, Akamai) apply specific rules to known crawlers: no cache, full content, no JavaScript challenge. These rules currently rely on IP lists and User-Agents — verifiable but bypassable.
With Web Bot Auth integrated at the CDN level, these rules can be applied on the basis of a real cryptographic verification. More robust. More reliable. And potentially, more flexibility to serve differentiated content depending on whether the visitor is a human, a legitimate crawler, or an unidentified bot.
What it does not solve (let us be honest)
Web Bot Auth is a real advance. But it is not a miracle solution — and claiming otherwise is not my style.
The duplicate content problem does not disappear. Bot authentication changes nothing about how Google evaluates your content quality, handles canonical tags, or processes duplicate versions of your pages. That is an SEO architecture problem, not a crawler identification problem.
Malicious bots will adapt. Cryptographic authentication blocks identity theft of legitimate crawlers. But scrapers that do not pretend to be Googlebot — those that simply declare themselves as a regular browser — continue exactly as before. Web Bot Auth does not solve scraping in general.
Adoption will take time. For this protocol to be useful, web servers, CDNs, WAFs, and analytics tools all need to integrate it. We are talking about an entire ecosystem to evolve. In practice, with our clients, we see that even well-established standards take years to be properly implemented.
“Perfect security does not exist. But each additional layer of verification makes the attack exponentially more costly for the attacker.” — fundamental principle in computer security
What you should do now, concretely
Web Bot Auth is not yet deployed. You have no immediate action to take on this specific protocol. But this evolution should prompt you to audit your technical stack right now — because the foundations you lay today determine your ability to integrate these changes tomorrow.
Start by analysing your server logs. If you are not regularly looking at your crawl logs, you are flying blind. Recommended tools: Screaming Frog Log File Analyser, or an ELK stack setup if you have the volume. Identify what is crawling your site, how often, and on which pages.
Check your robots.txt configuration and your crawl budget. Are you blocking the resources you should be blocking? Are you allowing crawling of low-value pages (filters, URL parameters, useless pagination pages)? An honest audit of your robots.txt often reveals years of stacked obsolete configurations.
Prepare your infrastructure for server-level authentication. If you use Nginx or Apache, familiarise yourself with request verification modules — and make sure you have read our guide on understanding HTTP headers and their impact on SEO, because that is exactly the level at which Web Bot Auth signatures will be verified. When the protocol becomes available, implementation will be faster the better your technical team understands the principle.
Clean up your analytics data now. Set up robust bot filters in Google Analytics 4, enable known bot filtering, and if you have significant volume, consider a server-side analytics tool (Matomo, Plausible) less dependent on JavaScript for data collection.

Three points to remember
1. Blind trust in User-Agents is a structural flaw. Web Bot Auth is not a marginal improvement — it is a rethinking of the trust principle that has governed interactions between your site and crawlers for 30 years.
2. Your crawl data is probably less reliable than you think. Even before Web Bot Auth is available, analysing your logs and cleaning your analytics data will give you a clearer picture of what Google is really crawling on your site.
3. Technical SEO is becoming industrialised. Cryptographic bot authentication, Core Web Vitals, crawl budget — these topics are no longer reserved for large-enterprise teams. An SME with a 50-page site needs to understand these mechanisms to avoid letting competitors gain an edge.
The next step for your site
After 15 years building and optimising sites for businesses in Normandy and across France, one observation stands out: the SMEs that get ahead of technical changes are not the ones with the biggest budgets. They are the ones that have their infrastructure audited regularly, before problems become visible in their results.
Web Bot Auth will change the way crawlers interact with your site. The question is not whether you need to prepare — it is when.
If you want us to audit your current technical configuration — crawl logs, robots.txt, crawl budget, bot filtering in your analytics — this is exactly the type of intervention we carry out at GDM-Pixel. Honest diagnosis, actionable recommendations, no full rebuild sold when a two-day audit is enough.
Contact our team — we will look at what your data really says about your Google visibility.






