




Cosa sta cambiando Google silenziosamente
Un nostro cliente ci ha chiamato di recente, irritato. Il suo sito riceveva migliaia di visite “fantasma” in Google Analytics — bot che falsavano i suoi dati, inquinavano le sue statistiche di conversione e rendevano inutilizzabili le sue decisioni di marketing. Problema classico. Soluzione attuale: approssimativa.
Perché oggi identificare un bot legittimo da un impostore è in gran parte una questione di cieca fiducia. Google dichiara di essere Google. Gli si dà fiducia — oppure no. E se qualcuno usurpa l’identità del Googlebot per fare scraping del tuo contenuto? Non hai praticamente nessun modo di dimostrarlo in tempo reale.
È esattamente questo problema che Google cerca di risolvere con Web Bot Auth, un protocollo crittografico sperimentale che potrebbe cambiare le regole del gioco per il SEO tecnico, la gestione dei crawler e l’affidabilità dei tuoi dati.
Ecco cosa significa concretamente per il tuo sito — e per la tua strategia di posizionamento SEO a lungo termine.
Il problema che nessuno risolveva davvero
Il robots.txt esiste dal 1994. Trent’anni. È lo stesso meccanismo di base: si posiziona un file di testo nella radice del sito, si elenca cosa i robot possono o non possono fare crawling. Semplice. Efficace per i bot che rispettano le regole.
Ma ecco la trappola classica: un bot malevolo non legge il tuo robots.txt. O meglio, lo legge, lo ignora e continua. E un bot che si spaccia per Googlebot? Il tuo server gli apre la porta senza batter ciglio.
Il metodo di verifica attuale raccomandato da Google stessa si basa su una risoluzione DNS inversa. In concreto: si prende l’indirizzo IP del crawler, si effettua una risoluzione DNS inversa per verificare che appartenga a Google, poi una risoluzione DNS diretta per confermare. Funziona. Ma è manuale, richiede tempo ed è totalmente inadatto a una verifica in tempo reale su larga scala.
Il risultato sul campo? La maggior parte degli hosting e dei sistemi di cache si fida dello User-Agent dichiarato. Il che significa che chiunque può dichiararsi Googlebot e beneficiare delle regole di eccezione configurate per i crawler legittimi. È la diretta prosecuzione di quanto descrivevamo in robots.txt, Google Search Console e schede prodotto: la nuova era del SEO tecnico — il livello dichiarativo non è più sufficiente.
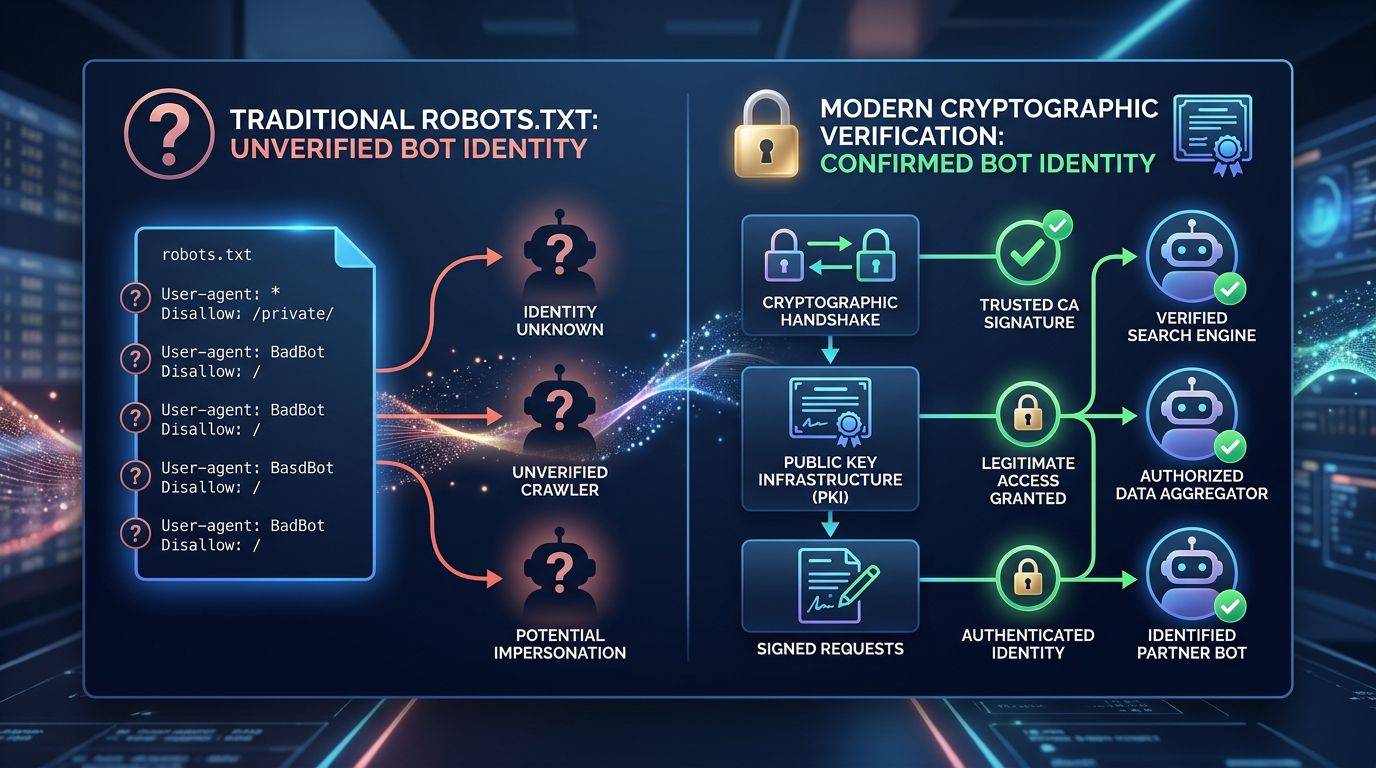
Web Bot Auth: il principio crittografico spiegato semplicemente
L’idea dietro Web Bot Auth è presa in prestito da un principio ben noto nella sicurezza informatica: la firma crittografica.
Quando il Googlebot visita il tuo sito, presenta una firma digitale generata con una chiave privata che solo Google possiede. Il tuo server può verificare questa firma usando la chiave pubblica corrispondente — disponibile e verificabile da chiunque. Se la firma è valida, è davvero Google. Se non lo è, è un impostore.
È lo stesso principio dei certificati SSL/TLS che proteggono le connessioni HTTPS. Ti fidi di un certificato perché è stato firmato da un’autorità riconosciuta, non perché il sito ti dice che è sicuro.
Ecco cosa cambia nella pratica:
La verifica diventa istantanea
Non serve più la laboriosa risoluzione DNS inversa. La firma è verificabile in pochi millisecondi, direttamente a livello di server o CDN. Quello che era un’operazione manuale post-crawl diventa una verifica in tempo reale.
L’usurpazione d’identità diventa (quasi) impossibile
Senza la chiave privata di Google, è impossibile generare una firma valida. Uno scraper che si dichiara Googlebot sarà immediatamente identificato come impostore — e potrai bloccarlo, registrarlo o servirgli un contenuto diverso.
Ogni motore può avere la propria identità verificabile
Web Bot Auth non è esclusivo di Google. Il protocollo è progettato per essere adottato da Bing, Yandex o qualsiasi crawler legittimo. Uno standard aperto, non uno strumento proprietario.
Cosa cambia per il tuo SEO tecnico
Siamo diretti: Web Bot Auth è ancora sperimentale. Google testa, documenta, itera. Non è distribuito su larga scala oggi. Ma ignorare questa evoluzione perché non è ancora in produzione è esattamente l’errore che fanno i team che inseguono sempre gli aggiornamenti invece di anticiparli.
Ecco dove diventa interessante per la tua strategia.
La gestione del crawl budget diventerà più precisa
Il crawl budget — la quantità di pagine che Googlebot accetta di eseguire il crawl sul tuo sito in un dato momento — è una risorsa limitata, particolarmente critica per i siti e-commerce con migliaia di referenze o i siti ad alto volume di contenuto.
Con Web Bot Auth, potrai distinguere con certezza i crawl legittimi da quelli parassitari. Risultato: i tuoi log del server diventano sfruttabili. Puoi misurare con precisione cosa Google esegue davvero il crawl, identificare le pagine ignorate e ottimizzare la tua architettura di conseguenza.
Oggi, molte analisi dei log sono inquinate da bot non identificati che si spacciano per crawler legittimi. Le tue decisioni di architettura SEO si basano su dati parzialmente falsati. Potresti non saperlo — ma è così.
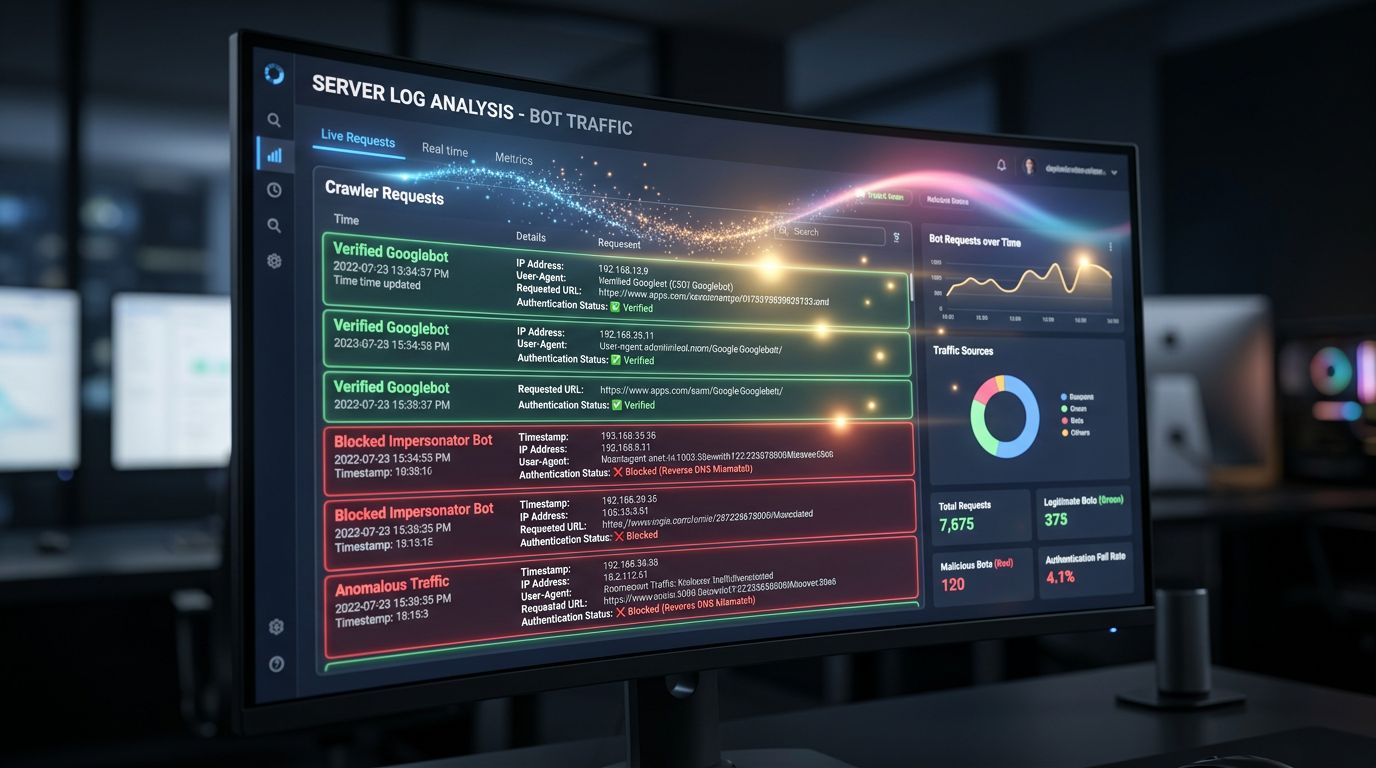
La qualità dei tuoi dati analitici migliorerà
Quel cliente di cui parlavo nell’introduzione — i suoi dati falsati dai bot — è un problema che Web Bot Auth attacca direttamente. Quando puoi identificare con certezza le richieste dei crawler legittimi, puoi escluderle correttamente dalle tue analisi del traffico.
Oggi, i filtri anti-bot in Google Analytics o negli strumenti di web analytics si basano su liste nere, soglie comportamentali ed euristiche. È imperfetto. Una verifica crittografica è binaria: legittimo o no. I tuoi tassi di rimbalzo, le conversioni, i dati di sessione — tutto diventa più affidabile.
Le regole di cache e CDN si evolveranno
Molte configurazioni CDN (Cloudflare, Fastly, Akamai) applicano regole specifiche ai crawler noti: nessuna cache, contenuto completo, nessuna sfida JavaScript. Queste regole si basano attualmente su liste di IP e User-Agent — verificabili, ma aggirabili.
Con Web Bot Auth integrato a livello CDN, queste regole potranno applicarsi sulla base di una verifica crittografica reale. Più robusta. Più affidabile. E potenzialmente, più flessibilità per servire contenuti differenziati a seconda che il visitatore sia un umano, un crawler legittimo o un bot non identificato.
Cosa non risolve (siamo onesti)
Web Bot Auth è un vero progresso. Ma non è una soluzione miracolosa — e prometterlo non è il mio stile.
Il problema del contenuto duplicato non scompare. L’autenticazione dei bot non cambia nulla nel modo in cui Google valuta la qualità del tuo contenuto, gestisce i tag canonici o tratta le versioni duplicate delle tue pagine. È un problema di architettura SEO, non di identificazione dei crawler.
I bot malevoli si adatteranno. L’autenticazione crittografica blocca l’usurpazione d’identità dei crawler legittimi. Ma gli scraper che non pretendono di essere Googlebot — quelli che si dichiarano semplicemente come un browser ordinario — continuano esattamente come prima. Web Bot Auth non risolve lo scraping in generale.
L’adozione richiederà tempo. Perché questo protocollo sia utile, i server web, i CDN, i WAF e gli strumenti di analisi devono integrarlo. Si parla di un intero ecosistema da far evolvere. Nella pratica, con i nostri clienti, vediamo che anche gli standard ben consolidati impiegano anni per essere implementati correttamente.
“La sicurezza perfetta non esiste. Ma ogni strato aggiuntivo di verifica rende l’attacco esponenzialmente più costoso per l’attaccante.” — principio fondamentale nella sicurezza informatica
Cosa dovresti fare ora, concretamente
Web Bot Auth non è ancora distribuito. Non hai nessuna azione immediata da intraprendere su questo protocollo specifico. Ma questa evoluzione dovrebbe spingerti ad auditare il tuo stack tecnico adesso — perché le fondamenta che poni oggi determinano la tua capacità di integrare questi cambiamenti domani.
Inizia analizzando i tuoi log del server. Se non guardi regolarmente i tuoi log di crawl, stai operando alla cieca. Strumenti consigliati: Screaming Frog Log File Analyser, o una configurazione ELK stack se hai il volume. Identifica cosa fa crawling del tuo sito, con quale frequenza e su quali pagine.
Verifica la tua configurazione robots.txt e il tuo crawl budget. Stai bloccando le risorse che dovresti bloccare? Stai permettendo il crawl di pagine a basso valore (filtri, parametri URL, pagine di paginazione inutili)? Un audit onesto del tuo robots.txt rivela spesso anni di configurazioni obsolete accumulate.
Prepara la tua infrastruttura all’autenticazione a livello di server. Se usi Nginx o Apache, familiarizzati con i moduli di verifica delle richieste — e assicurati di aver letto la nostra guida per comprendere le intestazioni HTTP e il loro impatto sul SEO, perché è esattamente a quel livello che le firme Web Bot Auth verranno verificate. Quando il protocollo sarà disponibile, l’implementazione sarà tanto più rapida quanto meglio il tuo team tecnico comprende il principio.
Pulisci i tuoi dati analitici ora. Configura filtri bot robusti in Google Analytics 4, attiva il filtraggio dei bot noti e, se hai un volume significativo, considera uno strumento di analisi lato server (Matomo, Plausible) meno dipendente da JavaScript per la raccolta.

Tre punti da ricordare
1. La cieca fiducia negli User-Agent è una falla strutturale. Web Bot Auth non è un miglioramento marginale — è una rifondazione del principio di fiducia che governa le interazioni tra il tuo sito e i crawler da 30 anni.
2. I tuoi dati di crawl sono probabilmente meno affidabili di quanto pensi. Anche prima che Web Bot Auth sia disponibile, analizzare i tuoi log e pulire i tuoi dati analitici ti darà una visione più chiara di cosa Google esegue davvero il crawl sul tuo sito.
3. Il SEO tecnico si industrializza. L’autenticazione crittografica dei bot, i Core Web Vitals, il crawl budget — questi argomenti non sono più riservati ai team delle grandi aziende. Una PMI con un sito di 50 pagine deve comprendere questi meccanismi per non lasciare che i suoi concorrenti prendano vantaggio.
Il prossimo passo per il tuo sito
Dopo 15 anni a costruire e ottimizzare siti per aziende in Normandia e in Francia, una constatazione si impone: le PMI che anticipano le evoluzioni tecniche non sono quelle con i budget maggiori. Sono quelle che fanno auditare la loro infrastruttura regolarmente, prima che i problemi diventino visibili nei loro risultati.
Web Bot Auth cambierà il modo in cui i crawler interagiscono con il tuo sito. La domanda non è se devi prepararti — è quando.
Se vuoi che auditassimo la tua configurazione tecnica attuale — log di crawl, robots.txt, crawl budget, filtraggio dei bot nelle tue analisi — è esattamente il tipo di intervento che conduciamo in GDM-Pixel. Diagnosi onesta, raccomandazioni azionabili, nessuna ristrutturazione venduta quando un audit di due giorni è sufficiente.
Contatta il nostro team — vedremo cosa i tuoi dati dicono davvero sulla tua visibilità su Google.






