




Was Google still verändert
Einer unserer Kunden rief uns kürzlich an, verärgert. Seine Website empfing Tausende von “Geister”-Besuchen in Google Analytics — Bots, die seine Daten verfälschten, seine Conversion-Statistiken verunreinigten und seine Marketingentscheidungen unbrauchbar machten. Ein klassisches Problem. Aktuelle Lösung: ungefähr.
Denn heute ist die Identifizierung eines legitimen Bots von einem Betrüger weitgehend eine Frage des blinden Vertrauens. Google erklärt, Google zu sein. Sie vertrauen ihm — oder nicht. Und wenn jemand die Identität des Googlebots usurpiert, um Ihre Inhalte zu scrapen? Sie haben praktisch keine Möglichkeit, dies in Echtzeit nachzuweisen.
Genau dieses Problem versucht Google mit Web Bot Auth zu lösen, einem experimentellen kryptografischen Protokoll, das die Spielregeln für technisches SEO, Crawler-Management und die Zuverlässigkeit Ihrer Daten verändern könnte.
Das bedeutet konkret für Ihre Website — und für Ihre langfristige SEO-Strategie.
Das Problem, das niemand wirklich löste
Die robots.txt existiert seit 1994. Dreißig Jahre. Es ist der gleiche grundlegende Mechanismus: Sie legen eine Textdatei im Stammverzeichnis Ihrer Website ab und listen auf, was Roboter crawlen können oder nicht. Einfach. Effektiv für Bots, die die Regeln befolgen.
Aber hier liegt die klassische Falle: Ein bösartiger Bot liest Ihre robots.txt nicht. Oder vielmehr liest er sie, ignoriert sie und macht weiter. Und ein Bot, der sich als Googlebot ausgibt? Ihr Server öffnet ihm die Tür ohne mit der Wimper zu zucken.
Die aktuelle Verifizierungsmethode, die Google selbst empfiehlt, basiert auf einer inversen DNS-Auflösung. Konkret: Sie nehmen die IP-Adresse des Crawlers, führen eine inverse DNS-Auflösung durch, um zu überprüfen, ob sie Google gehört, dann eine direkte DNS-Auflösung zur Bestätigung. Es funktioniert. Aber es ist manuell, zeitaufwendig und für eine Echtzeit-Verifizierung in großem Maßstab völlig ungeeignet.
Das Ergebnis in der Praxis? Die meisten Hosting-Anbieter und Cache-Systeme vertrauen dem deklarierten User-Agent. Das bedeutet, dass sich jeder als Googlebot deklarieren und von den Ausnahmeregeln profitieren kann, die Sie für legitime Crawler konfiguriert haben. Das ist die direkte Fortsetzung von dem, was wir in robots.txt, Google Search Console und Produktseiten: die neue Ära des technischen SEO beschrieben haben — die deklarative Schicht reicht nicht mehr aus.
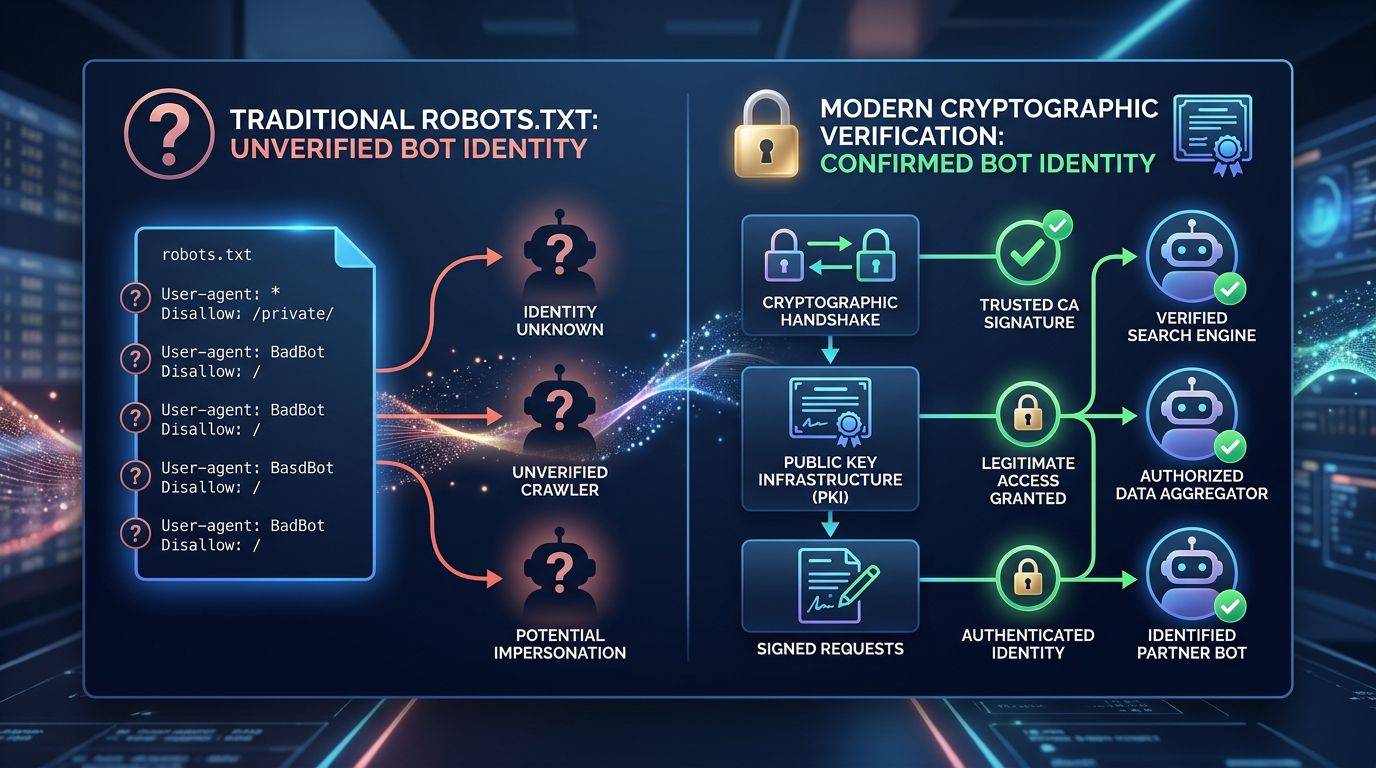
Web Bot Auth: das kryptografische Prinzip einfach erklärt
Die Idee hinter Web Bot Auth ist einem bekannten Prinzip der Informationssicherheit entlehnt: der kryptografischen Signatur.
Wenn der Googlebot Ihre Website besucht, präsentiert er eine digitale Signatur, die mit einem privaten Schlüssel generiert wurde, den nur Google besitzt. Ihr Server kann diese Signatur mit dem entsprechenden öffentlichen Schlüssel verifizieren — für jeden verfügbar und überprüfbar. Wenn die Signatur gültig ist, ist es wirklich Google. Wenn nicht, ist es ein Betrüger.
Das ist dasselbe Prinzip wie SSL/TLS-Zertifikate, die HTTPS-Verbindungen sichern. Sie vertrauen einem Zertifikat, weil es von einer anerkannten Autorität signiert wurde, nicht weil die Website Ihnen sagt, dass sie sicher ist.
Was sich in der Praxis ändert:
Die Verifizierung wird sofortig
Keine mühsame inverse DNS-Auflösung mehr. Die Signatur ist in wenigen Millisekunden direkt auf Server- oder CDN-Ebene überprüfbar. Was eine manuelle Post-Crawl-Operation war, wird zu einer Echtzeit-Verifizierung.
Identitätsdiebstahl wird (fast) unmöglich
Ohne den privaten Schlüssel von Google ist es unmöglich, eine gültige Signatur zu generieren. Ein Scraper, der sich als Googlebot deklariert, wird sofort als Betrüger identifiziert — und Sie können ihn blockieren, protokollieren oder ihm anderen Inhalt bereitstellen.
Jede Suchmaschine kann ihre eigene überprüfbare Identität haben
Web Bot Auth ist nicht exklusiv für Google. Das Protokoll ist so konzipiert, dass es von Bing, Yandex oder jedem legitimen Crawler übernommen werden kann. Ein offener Standard, kein proprietäres Werkzeug.
Was sich für Ihr technisches SEO ändert
Seien wir direkt: Web Bot Auth ist noch experimentell. Google testet, dokumentiert, iteriert. Es ist heute nicht in großem Maßstab eingesetzt. Aber diese Entwicklung zu ignorieren, weil sie noch nicht in der Produktion ist, ist genau der Fehler, den Teams machen, die immer hinter Updates herlaufen, anstatt sie zu antizipieren.
Hier wird es für Ihre Strategie interessant.
Das Crawl-Budget-Management wird präziser
Das Crawl-Budget — die Anzahl der Seiten, die Googlebot in einem bestimmten Zeitraum auf Ihrer Website zu crawlen bereit ist — ist eine begrenzte Ressource, besonders kritisch für E-Commerce-Websites mit Tausenden von Referenzen oder Websites mit hohem Inhaltsvolumen.
Mit Web Bot Auth können Sie mit Sicherheit legitime Crawls von parasitären unterscheiden. Ergebnis: Ihre Server-Logs werden verwertbar. Sie können genau messen, was Google wirklich crawlt, ignorierte Seiten identifizieren und Ihre Architektur entsprechend optimieren.
Heute sind viele Log-Analysen durch nicht identifizierte Bots verunreinigt, die sich als legitime Crawler ausgeben. Ihre SEO-Architekturentscheidungen basieren auf teilweise verfälschten Daten. Sie wissen es vielleicht nicht — aber das ist der Fall.
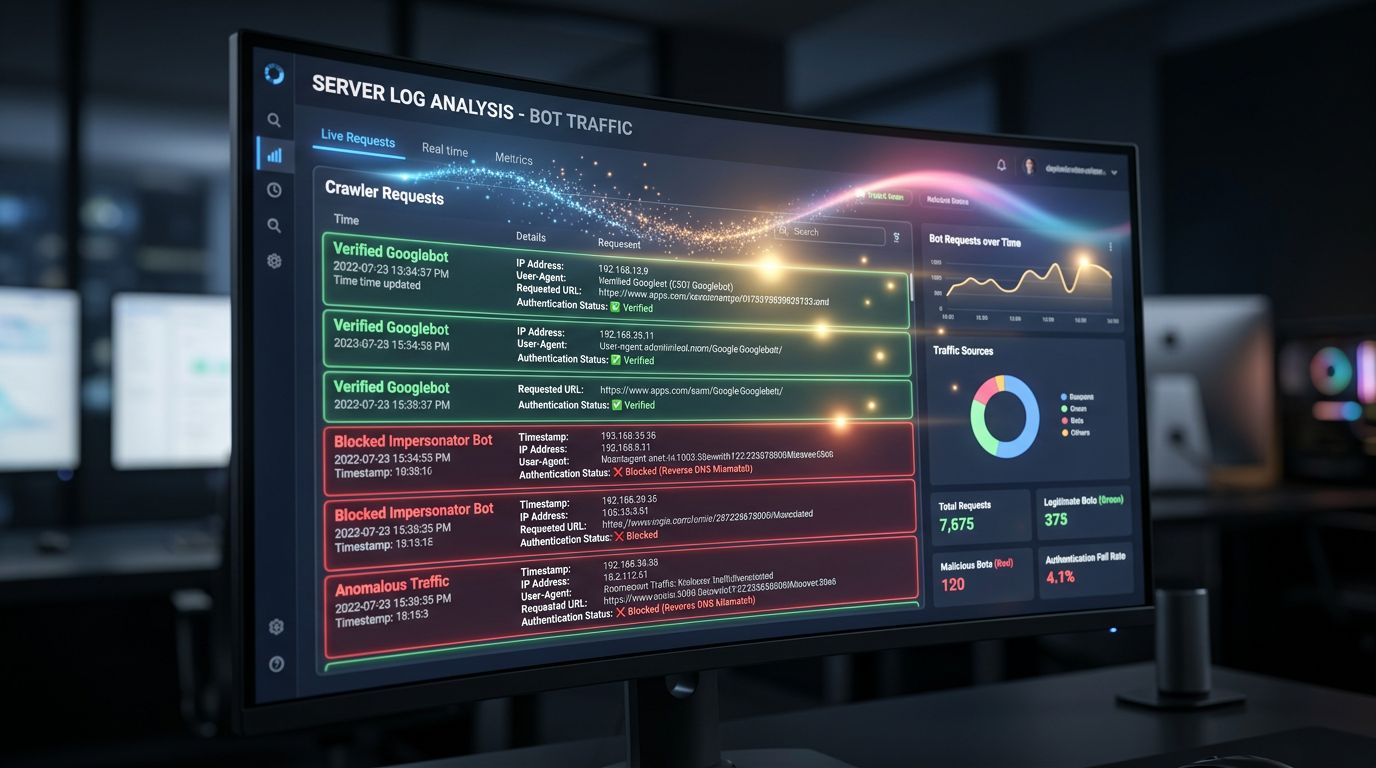
Die Qualität Ihrer Analytics-Daten wird sich verbessern
Dieser Kunde, von dem ich in der Einleitung sprach — seine durch Bots verfälschten Daten — ist ein Problem, das Web Bot Auth direkt angeht. Wenn Sie die Anfragen legitimer Crawler mit Sicherheit identifizieren können, können Sie sie sauber aus Ihren Traffic-Analysen ausschließen.
Heute basieren Anti-Bot-Filter in Google Analytics oder Ihren Web-Analytics-Tools auf Blacklists, Verhaltens-Schwellenwerten und Heuristiken. Das ist unvollkommen. Eine kryptografische Verifizierung ist binär: legitim oder nicht. Ihre Absprungraten, Conversions, Sitzungsdaten — alles wird zuverlässiger.
Cache- und CDN-Regeln werden sich weiterentwickeln
Viele CDN-Konfigurationen (Cloudflare, Fastly, Akamai) wenden spezifische Regeln für bekannte Crawler an: kein Cache, vollständiger Inhalt, keine JavaScript-Challenge. Diese Regeln basieren derzeit auf IP-Listen und User-Agents — überprüfbar, aber umgehbar.
Mit Web Bot Auth auf CDN-Ebene integriert können diese Regeln auf der Grundlage einer echten kryptografischen Verifizierung angewendet werden. Robuster. Zuverlässiger. Und potenziell mehr Flexibilität, um differenzierte Inhalte je nachdem bereitzustellen, ob der Besucher ein Mensch, ein legitimer Crawler oder ein nicht identifizierter Bot ist.
Was es nicht löst (seien wir ehrlich)
Web Bot Auth ist ein echter Fortschritt. Aber es ist keine Wunderlösung — und das Gegenteil zu versprechen entspricht nicht meinem Stil.
Das Problem des duplizierten Inhalts verschwindet nicht. Bot-Authentifizierung ändert nichts daran, wie Google die Qualität Ihrer Inhalte bewertet, mit kanonischen Tags umgeht oder duplizierte Versionen Ihrer Seiten behandelt. Das ist ein SEO-Architekturproblem, kein Crawler-Identifizierungsproblem.
Bösartige Bots werden sich anpassen. Kryptografische Authentifizierung blockiert den Identitätsdiebstahl legitimer Crawler. Aber Scraper, die nicht vorgeben, Googlebot zu sein — die sich einfach als normaler Browser deklarieren — machen genau wie bisher weiter. Web Bot Auth löst Scraping im Allgemeinen nicht.
Die Einführung wird Zeit brauchen. Damit dieses Protokoll nützlich ist, müssen Web-Server, CDNs, WAFs und Analyse-Tools es integrieren. Wir sprechen von einem gesamten Ökosystem, das sich weiterentwickeln muss. In der Praxis sehen wir mit unseren Kunden, dass selbst gut etablierte Standards Jahre brauchen, um korrekt implementiert zu werden.
“Perfekte Sicherheit existiert nicht. Aber jede zusätzliche Verifizierungsschicht macht den Angriff für den Angreifer exponentiell kostspieliger.” — grundlegendes Prinzip der Informationssicherheit
Was Sie jetzt konkret tun sollten
Web Bot Auth ist noch nicht eingesetzt. Sie haben keine sofortige Maßnahme bei diesem spezifischen Protokoll zu ergreifen. Aber diese Entwicklung sollte Sie dazu veranlassen, Ihren technischen Stack jetzt zu auditieren — denn die Grundlagen, die Sie heute legen, bestimmen Ihre Fähigkeit, diese Änderungen morgen zu integrieren.
Beginnen Sie mit der Analyse Ihrer Server-Logs. Wenn Sie Ihre Crawl-Logs nicht regelmäßig überprüfen, navigieren Sie blind. Empfohlene Tools: Screaming Frog Log File Analyser oder ein ELK-Stack-Setup, wenn Sie das Volumen haben. Identifizieren Sie, was Ihre Website crawlt, wie häufig und auf welchen Seiten.
Überprüfen Sie Ihre robots.txt-Konfiguration und Ihr Crawl-Budget. Blockieren Sie die Ressourcen, die Sie blockieren sollten? Erlauben Sie das Crawlen von Seiten mit geringem Wert (Filter, URL-Parameter, nutzlose Paginierungsseiten)? Ein ehrliches Audit Ihrer robots.txt offenbart oft Jahre von gestapelten veralteten Konfigurationen.
Bereiten Sie Ihre Infrastruktur auf die Authentifizierung auf Server-Ebene vor. Wenn Sie Nginx oder Apache verwenden, machen Sie sich mit den Anfrage-Verifizierungsmodulen vertraut — und stellen Sie sicher, dass Sie unseren Leitfaden zum Verständnis von HTTP-Headern und ihrem Einfluss auf SEO gelesen haben, denn genau auf dieser Ebene werden die Web Bot Auth-Signaturen verifiziert. Wenn das Protokoll verfügbar ist, wird die Implementierung umso schneller sein, je besser Ihr technisches Team das Prinzip versteht.
Bereinigen Sie Ihre Analytics-Daten jetzt. Richten Sie robuste Bot-Filter in Google Analytics 4 ein, aktivieren Sie die Filterung bekannter Bots und erwägen Sie, wenn Sie ein signifikantes Volumen haben, ein serverseitiges Analyse-Tool (Matomo, Plausible), das weniger auf JavaScript zur Datenerfassung angewiesen ist.

Drei Punkte zum Merken
1. Blindes Vertrauen in User-Agents ist ein struktureller Fehler. Web Bot Auth ist keine marginale Verbesserung — es ist eine Überarbeitung des Vertrauensprinzips, das seit 30 Jahren die Interaktionen zwischen Ihrer Website und den Crawlern regiert.
2. Ihre Crawl-Daten sind wahrscheinlich weniger zuverlässig, als Sie denken. Noch bevor Web Bot Auth verfügbar ist, wird Ihnen die Analyse Ihrer Logs und die Bereinigung Ihrer Analytics-Daten ein klareres Bild davon geben, was Google wirklich auf Ihrer Website crawlt.
3. Technisches SEO industrialisiert sich. Kryptografische Bot-Authentifizierung, Core Web Vitals, Crawl-Budget — diese Themen sind nicht mehr großen Unternehmens-Teams vorbehalten. Ein KMU mit einer 50-Seiten-Website muss diese Mechanismen verstehen, um Konkurrenten keinen Vorteil zu überlassen.
Der nächste Schritt für Ihre Website
Nach 15 Jahren des Aufbaus und der Optimierung von Websites für Unternehmen in der Normandie und in Frankreich zeigt sich eine Erkenntnis: Die KMUs, die technischen Entwicklungen voraus sind, sind nicht die mit den größten Budgets. Es sind die, die ihre Infrastruktur regelmäßig auditieren lassen, bevor Probleme in ihren Ergebnissen sichtbar werden.
Web Bot Auth wird die Art und Weise verändern, wie Crawler mit Ihrer Website interagieren. Die Frage ist nicht, ob Sie sich darauf vorbereiten müssen — sondern wann.
Wenn Sie möchten, dass wir Ihre aktuelle technische Konfiguration auditieren — Crawl-Logs, robots.txt, Crawl-Budget, Bot-Filterung in Ihren Analytics — ist das genau die Art von Eingriff, die wir bei GDM-Pixel durchführen. Ehrliche Diagnose, umsetzbare Empfehlungen, keine Komplettrenovierung verkauft, wenn ein zweitägiges Audit ausreicht.
Kontaktieren Sie unser Team — wir schauen uns an, was Ihre Daten wirklich über Ihre Google-Sichtbarkeit aussagen.






