




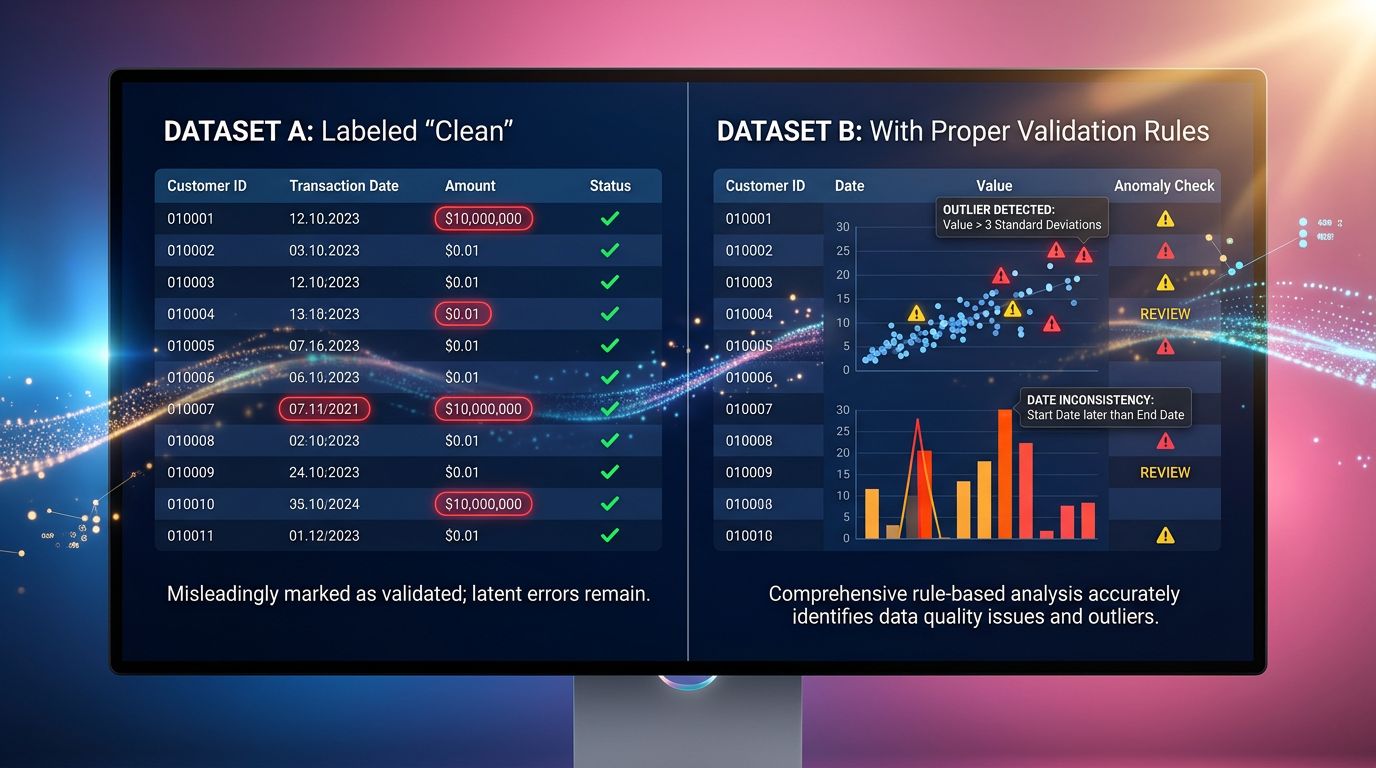
La fila limpia que esconde un problema sucio
Un cliente nos contactó hace unos meses. Había implementado un scraper para vigilar los precios de sus competidores — unas cincuenta referencias, nada muy complejo. El script se ejecutaba cada noche, los datos aterrizaban en una hoja de Google Sheets, y todo parecía perfecto.
Filas bien rellenas. Sin errores. Ningún campo vacío.
Salvo que sus precios estaban sistemáticamente por debajo del mercado desde hacía tres semanas. Perdía margen sin entender por qué.
El scraper había recuperado las URLs correctas. Había parseado los selectores CSS correctos. Había devuelto valores numéricos limpios. Y sin embargo — recuperaba los precios de la versión en caché del sitio del competidor, no los precios en tiempo real. El competidor había cambiado su estructura de renderizado del lado del cliente. El scraper, en cambio, no había visto nada.
Una fila limpia no significa una fila correcta.
Es la trampa número uno del scraping de datos. Y si automatizas decisiones de negocio basándote en estos datos — tarificación, vigilancia competitiva, seguimiento de stock — quizás estés conduciendo a ciegas desde hace semanas.
Por qué tu scraper te miente con una sonrisa
El problema con los scrapers mal validados es que no se caen. Entregan. Regularmente, limpiamente, sin levantar la más mínima excepción.
Estos son los escenarios que encontramos con más frecuencia en nuestras auditorías:
El selector CSS que sobrevive a la muerte del contenido bueno. El sitio objetivo ha actualizado su plantilla. El antiguo div.price sigue existiendo — pero ahora contiene un valor por defecto, un placeholder, o peor, un cero. Tu script lo recupera sin pestañear.
El renderizado JavaScript diferido. Cada vez más sitios cargan sus precios, sus stocks o sus descripciones mediante llamadas API asíncronas. Un scraper básico basado en requests + BeautifulSoup recupera el HTML inicial — antes de que JavaScript haya tenido tiempo de poblar los campos. Resultado: etiquetas vacías o valores de fallback. Limpios. Falsos.
El contenido geolocalizado o personalizado. El sitio detecta tu IP, tu user-agent, o la ausencia de cookie de sesión. Te sirve una versión recortada, una página de redirección, o una oferta distinta de la que ve un cliente real. Tu scraper no sabe que está en la sala de espera mientras los clientes reales ya están sentados a la mesa.
El rate limiting silencioso. Algunos sitios no bloquean tu scraper — lo ralentizan y le sirven datos degradados. Sin error 429, sin timeout. Solo valores aproximados o caducados. Indetectables si no validas activamente el contenido devuelto.

Lo que “validar una fila” realmente significa
La validación de datos se reduce a menudo a: “¿está vacío el campo?” Es necesario. Está muy lejos de ser suficiente.
Esto es lo que una validación seria debe cubrir:
Verificar la plausibilidad, no solo la presencia
Un precio de 0,00€ es un valor presente. También es un valor absurdo para el 99% de los catálogos. Un precio de 99999€ para un producto que valía 49€ la semana pasada merece una alerta, no una inserción silenciosa en la base de datos.
Establece reglas de plausibilidad de negocio. Para un catálogo de e-commerce, se parece a:
- Precio > 0 y < umbral_máximo_categoría
- Variación vs valor anterior < X% (alerta si se supera)
- Unidad coherente con la categoría (nada de precios en céntimos donde se esperan euros)
No es desarrollo complejo. Es lógica de negocio traducida en condiciones. Pero requiere conocer tus datos — y ahí es donde muchos proyectos de scraping fracasan desde el principio.
Controlar el contexto de la página, no solo el campo objetivo
Antes de extraer tu valor objetivo, verifica que estás en la página correcta. Parece evidente. No lo es en producción.
Algunos chequeos a integrar sistemáticamente:
- ¿Coincide el título de la página con el producto esperado?
- ¿El código HTTP de la respuesta es realmente un 200 (y no un 200 disfrazado que esconde una página de error personalizada)?
- ¿La estructura del DOM se corresponde con lo que esperas — al menos en los elementos estructurales?
Un sitio que devuelve una página “Producto no disponible” con estado 200 y un campo precio vacío a 0 — tu scraper básico se lo va a tragar sin inmutarse.
Marcar con fecha y versionar tus datos
Cada fila extraída debería llevar un timestamp de extracción y, idealmente, un hash del contenido bruto de la página. ¿Por qué?
Porque cuando detectes una anomalía tres semanas después, necesitas saber desde cuándo existe. Y si el sitio ha cambiado su estructura, querrás poder comparar el HTML de antes y después.
Sin historial, depuras a ciegas. Con un historial aunque sea mínimo, tienes un hilo del que tirar.
El verdadero coste de un dato falso que parece correcto
Volvamos a nuestro cliente. Tres semanas de precios desalineados a la baja en cincuenta referencias. En algunas referencias de alto margen, la diferencia era del 8 al 12%.
No vamos a hacer el cálculo exacto aquí — esas cifras le pertenecen. Pero el orden de magnitud son varios miles de euros de margen perdido. Sobre un pipeline de datos que funcionaba perfectamente, sin ninguna alerta, sin ningún log de error.
“El peor bug no es el que hace caer tu sistema. Es el que lo deja funcionando dándote la ilusión de que todo va bien.”
Esto vale para el scraping. Vale para cualquier pipeline de datos automatizado — flujos EDI, sincronización ERP, exportaciones contables. El dato silenciosamente falso es infinitamente más peligroso que el error ruidoso.
Un error ruidoso se corrige en el día. Un error silencioso se descubre durante una auditoría, un balance, o cuando un cliente te señala un problema que deberías haber visto hace semanas.
Cómo estructuramos un scraper que desconfía de sí mismo
En nuestros proyectos de automatización — ya sea para vigilancia competitiva, agregación de contenido o sincronización de catálogos — hemos aprendido a construir scrapers paranoicos por diseño.
Estos son los principios que aplicamos sistemáticamente:
Separar la extracción de la validación
Nunca insertar un dato extraído directamente en la base de datos o en un flujo de negocio. Pasar siempre por una etapa de validación intermedia — aunque sea mínima. Extracción → staging → validación → producción.
Definir un “contrato de datos” antes de codificar
Antes de escribir la primera línea de código, documenta lo que esperas: tipos, formatos, rangos de valores, dependencias entre campos. Este contrato se convierte en tu spec de validación. Si tu dato no respeta el contrato, no pasa.
Loguear las anomalías, no solo los errores
Un campo null es un error. Un precio a cero en un producto activo es una anomalía. Un precio que aumenta un 300% en una noche es una anomalía. Tus logs deben capturar los dos niveles — y alertarte de forma diferente según la criticidad.
Prever un modo “cuarentena”
Las filas que no pasan la validación no se eliminan — se ponen en cuarentena con el motivo del rechazo. Así puedes analizarlas, entender si es un bug de tu scraper o un cambio real del lado fuente, y decidir con conocimiento de causa.
Probar con datos conocidos
Antes de desplegar en producción, prueba tu scraper en páginas cuyos valores exactos conozcas. Compara el resultado extraído con el valor esperado. Es básico. A menudo se omite. Y es lo que te permite detectar los problemas de renderizado JavaScript o de personalización antes de que lleguen a producción.
Los tres reflejos a adoptar desde ahora
Si tienes un pipeline de datos automatizado en producción — scraper, flujo EDI, sincronización API — esto es lo que te aconsejo verificar esta semana:
Reflejo 1: Audita tus datos históricos. Toma los últimos 30 días. Busca valores a cero, valores idénticos en periodos sospechosos, rupturas de tendencia anormales. Si no puedes hacer esta auditoría por falta de historial — esa es tu primera obra.
Reflejo 2: Añade una regla de plausibilidad sobre tus campos críticos. Solo una. La que protege tu decisión de negocio más sensible. Precio, stock, estado de disponibilidad — elige y blinda.
Reflejo 3: Implementa una alerta sobre las variaciones anormales. No hace falta un sistema complejo. Un simple script que compara el valor del día con la mediana de los 7 últimos días y te envía un mensaje a Discord si la diferencia supera un umbral. Lo hemos implementado para varios clientes en menos de dos horas.
Lo que esto cambia concretamente
Un scraper que desconfía de sí mismo, es más tiempo de desarrollo al principio. También es mucho menos tiempo pasado depurando anomalías en producción, explicando a un cliente por qué sus datos eran falsos desde hacía tres semanas, o reconstruyendo manualmente lo que debería haberse automatizado correctamente.
En nuestra agencia, hemos elegido integrar estas capas de validación desde la fase de diseño — no como parche. Alarga las specs un 20%. Divide los incidentes de producción por un factor que ya no nos apetece calcular.
El dato limpio es una ilusión si no defines tú mismo lo que “limpio” significa.
Tu scraper no sabe qué es un precio coherente para tu catálogo. Tu flujo EDI no sabe que un stock negativo es imposible en tu negocio. Tu sincronización API no sabe que ese campo en concreto nunca debería estar vacío.
Tú sí. Entonces, codifícalo.
¿Tienes un pipeline de datos automatizado y quieres verificar si es realmente fiable? Hacemos auditorías técnicas focalizadas — no rediseños completos cuando no son necesarios. Contacta GDM-Pixel para un diagnóstico honesto. Te diremos qué aguanta y qué merece ser blindado.






