




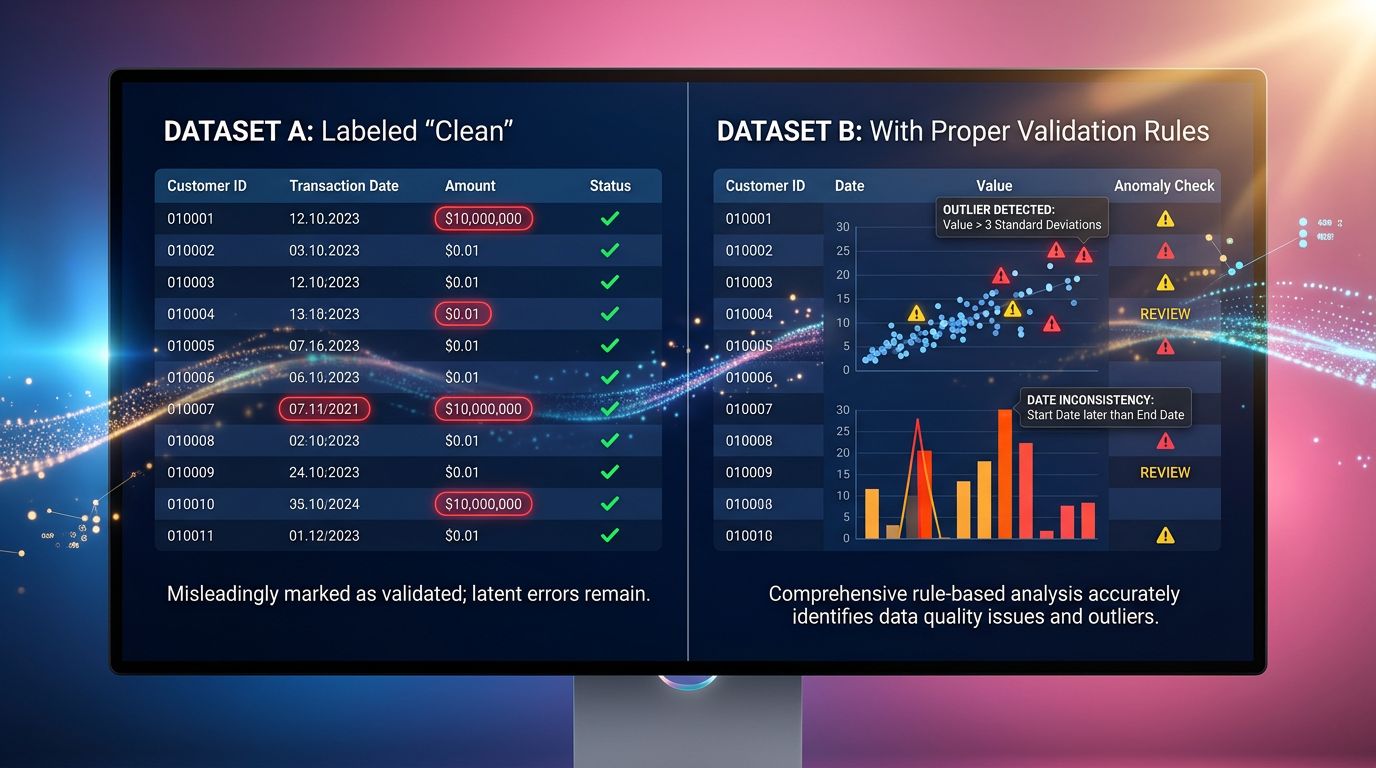
La ligne propre qui cache un problème sale
Un de nos clients nous a contactés il y a quelques mois. Il avait mis en place un scraper pour surveiller les prix de ses concurrents — une cinquantaine de références, rien de très complexe. Le script tournait chaque nuit, les données atterrissaient dans un Google Sheet, et tout semblait parfait.
Lignes bien remplies. Aucune erreur. Aucun champ vide.
Sauf que ses prix étaient systématiquement en dessous du marché depuis trois semaines. Il perdait de la marge sans comprendre pourquoi.
Le scraper avait récupéré les bonnes URLs. Il avait parsé les bons sélecteurs CSS. Il avait retourné des valeurs numériques propres. Et pourtant — il récupérait les prix de la version mise en cache du site concurrent, pas les prix en temps réel. Le concurrent avait changé sa structure de rendu côté client. Le scraper, lui, n’avait rien vu.
Une ligne propre ne signifie pas une ligne correcte.
C’est le piège numéro un du scraping de données. Et si vous automatisez des décisions métier sur la base de ces données — tarification, veille concurrentielle, suivi de stock — vous roulez peut-être à l’aveugle depuis des semaines.
Pourquoi votre scraper vous ment avec le sourire
Le problème avec les scrapers mal validés, c’est qu’ils ne plantent pas. Ils livrent. Régulièrement, proprement, sans lever la moindre exception.
Voici les scénarios qu’on rencontre le plus souvent dans nos audits :
Le sélecteur CSS qui survit à la mort du bon contenu. Le site cible a mis à jour son template. L’ancien div.price existe toujours — mais il contient maintenant une valeur par défaut, un placeholder, ou pire, un zéro. Votre script le récupère sans broncher.
Le rendu JavaScript différé. De plus en plus de sites chargent leurs prix, leurs stocks ou leurs descriptions via des appels API asynchrones. Un scraper basique basé sur requests + BeautifulSoup récupère le HTML initial — avant que le JavaScript ait eu le temps de peupler les champs. Résultat : des balises vides ou des valeurs de fallback. Propres. Fausses.
Le contenu géolocalisé ou personnalisé. Le site détecte votre IP, votre user-agent, ou l’absence de cookie de session. Il vous sert une version allégée, une page de redirection, ou une offre différente de celle que voit un vrai client. Votre scraper ne sait pas qu’il est dans la salle d’attente pendant que les vrais clients sont déjà à table.
Le rate limiting silencieux. Certains sites ne bloquent pas votre scraper — ils le ralentissent et lui servent des données dégradées. Pas d’erreur 429, pas de timeout. Juste des valeurs approximatives ou périmées. Indétectables si vous ne validez pas activement le contenu retourné.

Ce que “valider une ligne” veut vraiment dire
La validation de données, c’est souvent réduit à : “est-ce que le champ est vide ?” C’est nécessaire. C’est loin d’être suffisant.
Voici ce qu’une validation sérieuse doit couvrir :
Vérifier la vraisemblance, pas seulement la présence
Un prix à 0.00€ est une valeur présente. C’est aussi une valeur absurde pour 99% des catalogues. Un prix à 99999€ pour un produit qui valait 49€ la semaine dernière mérite un flag, pas une insertion silencieuse en base.
Mettez en place des règles de plausibilité métier. Pour un catalogue e-commerce, ça ressemble à :
- Prix > 0 et < seuil_max_catégorie
- Variation vs valeur précédente < X% (alerte si dépassement)
- Unité cohérente avec la catégorie (pas de prix en centimes là où on attend des euros)
Ce n’est pas du développement complexe. C’est de la logique métier traduite en conditions. Mais ça demande de connaître votre donnée — et c’est là que beaucoup de projets de scraping échouent dès le départ.
Contrôler le contexte de la page, pas seulement le champ cible
Avant d’extraire votre valeur cible, vérifiez que vous êtes bien sur la bonne page. Ça paraît évident. Ça ne l’est pas en production.
Quelques checks à intégrer systématiquement :
- Le titre de la page correspond-il au produit attendu ?
- Le code HTTP de la réponse est-il bien un 200 (et pas un 200 déguisé qui cache une page d’erreur personnalisée) ?
- La structure du DOM correspond-elle à ce qu’on attend — au moins sur les éléments structurants ?
Un site qui retourne une page “Produit non disponible” avec un status 200 et un champ prix vide à 0 — votre scraper basique va l’avaler sans sourciller.
Horodater et versionner vos données
Chaque ligne extraite devrait embarquer un timestamp d’extraction et, idéalement, un hash du contenu brut de la page. Pourquoi ?
Parce que quand vous détectez une anomalie trois semaines plus tard, vous avez besoin de savoir depuis quand elle existe. Et si le site a changé sa structure, vous voulez pouvoir comparer le HTML d’avant et d’après.
Sans historique, vous débuggez à l’aveugle. Avec un historique même minimal, vous avez un fil à tirer.
Le vrai coût d’une donnée fausse qui semble juste
Revenons à notre client. Trois semaines de prix sous-alignés sur cinquante références. Sur certaines références à forte marge, l’écart était de 8 à 12%.
On ne va pas faire le calcul exact ici — les chiffres lui appartiennent. Mais l’ordre de grandeur, c’est plusieurs milliers d’euros de marge perdue. Sur un pipeline de données qui tournait parfaitement, sans aucune alerte, sans aucun log d’erreur.
“Le pire bug n’est pas celui qui fait planter votre système. C’est celui qui le laisse tourner en vous donnant l’illusion que tout va bien.”
C’est valable pour le scraping. C’est valable pour n’importe quel pipeline de données automatisé — flux EDI, synchronisation ERP, exports comptables. La donnée silencieusement fausse est infiniment plus dangereuse que l’erreur bruyante.
Une erreur bruyante, vous la corrigez dans la journée. Une erreur silencieuse, vous la découvrez lors d’un audit, d’un bilan, ou quand un client vous signale un problème que vous auriez dû voir depuis des semaines.
Comment on structure un scraper qui se méfie de lui-même
Dans nos projets d’automatisation — que ce soit pour de la veille concurrentielle, de l’agrégation de contenu ou de la synchronisation de catalogues — on a appris à construire des scrapers paranoïaques par design.
Voici les principes qu’on applique systématiquement :
Séparer l’extraction de la validation
Ne jamais insérer une donnée extraite directement en base ou dans un flux métier. Toujours passer par une étape de validation intermédiaire — même minimale. Extraction → staging → validation → production.
Définir un “contrat de données” avant de coder
Avant d’écrire la première ligne de code, documentez ce que vous attendez : types, formats, plages de valeurs, dépendances entre champs. Ce contrat devient votre spec de validation. Si votre donnée ne respecte pas le contrat, elle ne passe pas.
Logger les anomalies, pas seulement les erreurs
Un champ null est une erreur. Un prix à zéro sur un produit actif est une anomalie. Un prix qui augmente de 300% en une nuit est une anomalie. Vos logs doivent capturer les deux niveaux — et vous alerter différemment selon la criticité.
Prévoir un mode “quarantaine”
Les lignes qui ne passent pas la validation ne sont pas supprimées — elles sont mises en quarantaine avec le motif de rejet. Vous pouvez ainsi les analyser, comprendre si c’est un bug de votre scraper ou un vrai changement côté source, et décider en connaissance de cause.
Tester avec des données connues
Avant de déployer en production, testez votre scraper sur des pages dont vous connaissez les valeurs exactes. Comparez le résultat extrait avec la valeur attendue. C’est basique. C’est souvent omis. Et c’est ce qui vous permet de détecter les problèmes de rendu JavaScript ou de personnalisation avant qu’ils arrivent en prod.
Les trois réflexes à adopter dès maintenant
Si vous avez un pipeline de données automatisé en production — scraper, flux EDI, synchronisation API — voici ce que je vous conseille de vérifier cette semaine :
Réflexe 1 : Auditez vos données historiques. Prenez les 30 derniers jours. Cherchez des valeurs à zéro, des valeurs identiques sur des périodes suspectes, des ruptures de tendance anormales. Si vous ne pouvez pas faire cet audit faute d’historique — c’est votre premier chantier.
Réflexe 2 : Ajoutez une règle de vraisemblance sur vos champs critiques. Juste une. Celle qui protège votre décision métier la plus sensible. Prix, stock, statut de disponibilité — choisissez et blindez.
Réflexe 3 : Mettez en place une alerte sur les variations anormales. Pas besoin d’un système complexe. Un simple script qui compare la valeur du jour avec la médiane des 7 derniers jours et vous envoie un message Discord si l’écart dépasse un seuil. On a mis ça en place pour plusieurs clients en moins de deux heures.
Ce que ça change concrètement
Un scraper qui se méfie de lui-même, c’est plus de temps de développement au départ. C’est aussi beaucoup moins de temps passé à débugger des anomalies en production, à expliquer à un client pourquoi ses données étaient fausses depuis trois semaines, ou à reconstituer manuellement ce qui aurait dû être automatisé proprement.
Dans notre agence, on a fait le choix d’intégrer ces couches de validation dès la phase de conception — pas en rattrapage. Ça allonge les specs de 20%. Ça divise les incidents de production par un facteur qu’on n’a plus vraiment envie de calculer.
La donnée propre est une illusion si vous ne définissez pas vous-même ce que “propre” signifie.
Votre scraper ne sait pas ce qu’est un prix cohérent pour votre catalogue. Votre flux EDI ne sait pas qu’un stock négatif est impossible dans votre métier. Votre synchronisation API ne sait pas que ce champ-là ne devrait jamais être vide.
Vous, si. Alors encodez-le.
Vous avez un pipeline de données automatisé et vous voulez vérifier s’il est réellement fiable ? On fait des audits techniques ciblés — pas des refontes complètes si ce n’est pas nécessaire. Contactez GDM-Pixel pour un diagnostic honnête. On vous dira ce qui tient et ce qui mérite d’être blindé.






