




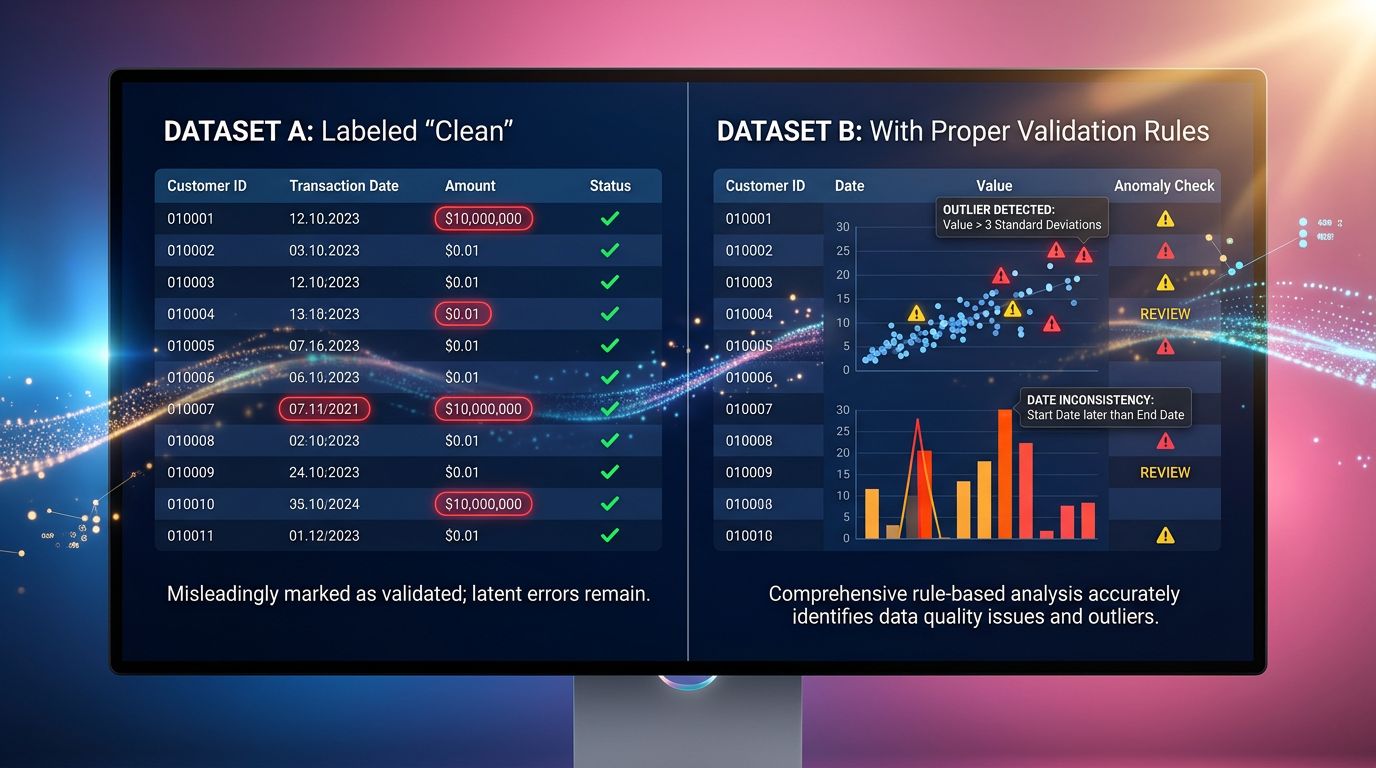
La riga pulita che nasconde un problema sporco
Un cliente ci ha contattato qualche mese fa. Aveva implementato uno scraper per monitorare i prezzi dei concorrenti — una cinquantina di riferimenti, niente di troppo complesso. Lo script girava ogni notte, i dati atterravano in un Google Sheet, e tutto sembrava perfetto.
Righe ben riempite. Nessun errore. Nessun campo vuoto.
Solo che i suoi prezzi erano sistematicamente sotto il mercato da tre settimane. Stava perdendo margine senza capire perché.
Lo scraper aveva recuperato le URL giuste. Aveva parsato i selettori CSS giusti. Aveva restituito valori numerici puliti. Eppure — recuperava i prezzi dalla versione in cache del sito concorrente, non i prezzi in tempo reale. Il concorrente aveva cambiato la sua struttura di rendering lato client. Lo scraper, invece, non aveva visto nulla.
Una riga pulita non significa una riga corretta.
È la trappola numero uno dello scraping di dati. E se automatizzi decisioni di business sulla base di questi dati — pricing, intelligence competitiva, monitoraggio scorte — potresti viaggiare alla cieca da settimane.
Perché il tuo scraper ti mente con il sorriso
Il problema con gli scraper mal validati è che non si schiantano. Consegnano. Regolarmente, in modo pulito, senza sollevare la minima eccezione.
Ecco gli scenari che incontriamo più spesso nei nostri audit:
Il selettore CSS che sopravvive alla morte del contenuto buono. Il sito target ha aggiornato il suo template. Il vecchio div.price esiste ancora — ma ora contiene un valore di default, un placeholder, o peggio, uno zero. Il tuo script lo recupera senza battere ciglio.
Il rendering JavaScript differito. Sempre più siti caricano i loro prezzi, le scorte o le descrizioni tramite chiamate API asincrone. Uno scraper di base basato su requests + BeautifulSoup recupera l’HTML iniziale — prima che JavaScript abbia avuto il tempo di popolare i campi. Risultato: tag vuoti o valori di fallback. Puliti. Sbagliati.
Il contenuto geolocalizzato o personalizzato. Il sito rileva il tuo IP, il tuo user-agent, o l’assenza di un cookie di sessione. Ti serve una versione ridotta, una pagina di redirect, o un’offerta diversa da quella che vede un vero cliente. Il tuo scraper non sa di essere in sala d’attesa mentre i veri clienti sono già a tavola.
Il rate limiting silenzioso. Alcuni siti non bloccano il tuo scraper — lo rallentano e gli servono dati degradati. Nessun errore 429, nessun timeout. Solo valori approssimativi o scaduti. Indetectabili se non validi attivamente il contenuto restituito.

Cosa significa davvero “validare una riga”
La validazione dei dati si riduce spesso a: “il campo è vuoto?” È necessario. È lontano dall’essere sufficiente.
Ecco cosa una validazione seria deve coprire:
Verificare la plausibilità, non solo la presenza
Un prezzo a 0,00€ è un valore presente. È anche un valore assurdo per il 99% dei cataloghi. Un prezzo a 99999€ per un prodotto che valeva 49€ la settimana scorsa merita un flag, non un inserimento silenzioso in banca dati.
Imposta regole di plausibilità di business. Per un catalogo e-commerce, assomiglia a:
- Prezzo > 0 e < soglia_max_categoria
- Variazione vs valore precedente < X% (allerta se superata)
- Unità coerente con la categoria (niente prezzi in centesimi dove ci si aspettano euro)
Non è sviluppo complesso. È logica di business tradotta in condizioni. Ma richiede di conoscere i propri dati — ed è qui che molti progetti di scraping falliscono fin dall’inizio.
Controllare il contesto della pagina, non solo il campo target
Prima di estrarre il tuo valore target, verifica di essere sulla pagina giusta. Sembra ovvio. Non lo è in produzione.
Alcuni controlli da integrare sistematicamente:
- Il titolo della pagina corrisponde al prodotto atteso?
- Il codice HTTP della risposta è davvero un 200 (e non un 200 mascherato che nasconde una pagina d’errore personalizzata)?
- La struttura del DOM corrisponde a ciò che ti aspetti — almeno sugli elementi strutturali?
Un sito che restituisce una pagina “Prodotto non disponibile” con stato 200 e un campo prezzo vuoto a 0 — il tuo scraper di base se lo ingoierà senza battere ciglio.
Datare e versionare i tuoi dati
Ogni riga estratta dovrebbe portare un timestamp di estrazione e, idealmente, un hash del contenuto grezzo della pagina. Perché?
Perché quando rilevi un’anomalia tre settimane dopo, devi sapere da quando esiste. E se il sito ha cambiato la sua struttura, vuoi poter confrontare l’HTML di prima e dopo.
Senza storico, fai debug alla cieca. Con uno storico anche minimo, hai un filo da tirare.
Il vero costo di un dato falso che sembra giusto
Torniamo al nostro cliente. Tre settimane di prezzi sotto-allineati su cinquanta riferimenti. Su alcuni riferimenti ad alto margine, lo scarto era dell’8-12%.
Non faremo il calcolo esatto qui — quei numeri gli appartengono. Ma l’ordine di grandezza è di diverse migliaia di euro di margine perso. Su una pipeline di dati che girava perfettamente, senza alcun alert, senza alcun log di errore.
“Il peggior bug non è quello che fa crashare il tuo sistema. È quello che lo lascia girare dandoti l’illusione che vada tutto bene.”
Vale per lo scraping. Vale per qualsiasi pipeline di dati automatizzata — flussi EDI, sincronizzazione ERP, esportazioni contabili. Il dato silenziosamente sbagliato è infinitamente più pericoloso dell’errore rumoroso.
Un errore rumoroso lo correggi in giornata. Un errore silenzioso lo scopri durante un audit, un bilancio, o quando un cliente ti segnala un problema che avresti dovuto vedere da settimane.
Come strutturiamo uno scraper che diffida di se stesso
Nei nostri progetti di automazione — che si tratti di intelligence competitiva, aggregazione di contenuti o sincronizzazione di cataloghi — abbiamo imparato a costruire scraper paranoici by design.
Ecco i principi che applichiamo sistematicamente:
Separare l’estrazione dalla validazione
Mai inserire un dato estratto direttamente in banca dati o in un flusso di business. Passare sempre attraverso una fase di validazione intermedia — anche minima. Estrazione → staging → validazione → produzione.
Definire un “contratto dati” prima di codificare
Prima di scrivere la prima riga di codice, documenta cosa ti aspetti: tipi, formati, intervalli di valori, dipendenze tra campi. Questo contratto diventa la tua spec di validazione. Se il tuo dato non rispetta il contratto, non passa.
Loggare le anomalie, non solo gli errori
Un campo null è un errore. Un prezzo a zero su un prodotto attivo è un’anomalia. Un prezzo che aumenta del 300% in una notte è un’anomalia. I tuoi log devono catturare i due livelli — e allertarti diversamente in base alla criticità.
Prevedere una modalità “quarantena”
Le righe che non passano la validazione non vengono cancellate — vengono messe in quarantena con il motivo del rifiuto. Puoi così analizzarle, capire se è un bug del tuo scraper o un vero cambiamento lato sorgente, e decidere con cognizione di causa.
Testare con dati noti
Prima di deployare in produzione, testa il tuo scraper su pagine di cui conosci i valori esatti. Confronta il risultato estratto con il valore atteso. È basico. Viene spesso omesso. Ed è ciò che ti permette di rilevare i problemi di rendering JavaScript o di personalizzazione prima che arrivino in produzione.
I tre riflessi da adottare fin da subito
Se hai una pipeline di dati automatizzata in produzione — scraper, flusso EDI, sincronizzazione API — ecco cosa ti consiglio di verificare questa settimana:
Riflesso 1: Fai l’audit dei tuoi dati storici. Prendi gli ultimi 30 giorni. Cerca valori a zero, valori identici su periodi sospetti, rotture di tendenza anormali. Se non puoi fare questo audit per mancanza di storico — è il tuo primo cantiere.
Riflesso 2: Aggiungi una regola di plausibilità sui tuoi campi critici. Solo una. Quella che protegge la tua decisione di business più sensibile. Prezzo, scorta, stato di disponibilità — scegli e blinda.
Riflesso 3: Implementa un alert sulle variazioni anormali. Non serve un sistema complesso. Un semplice script che confronta il valore del giorno con la mediana degli ultimi 7 giorni e ti invia un messaggio Discord se lo scarto supera una soglia. L’abbiamo implementato per diversi clienti in meno di due ore.
Cosa cambia concretamente
Uno scraper che diffida di se stesso significa più tempo di sviluppo all’inizio. Significa anche molto meno tempo passato a fare debug di anomalie in produzione, a spiegare a un cliente perché i suoi dati erano sbagliati da tre settimane, o a ricostruire manualmente ciò che avrebbe dovuto essere automatizzato come si deve.
Nella nostra agenzia, abbiamo scelto di integrare questi layer di validazione fin dalla fase di progettazione — non come patch. Allunga le spec del 20%. Divide gli incidenti di produzione per un fattore che non abbiamo più voglia di calcolare.
Il dato pulito è un’illusione se non definisci tu stesso cosa significa “pulito”.
Il tuo scraper non sa cos’è un prezzo coerente per il tuo catalogo. Il tuo flusso EDI non sa che una scorta negativa è impossibile nel tuo mestiere. La tua sincronizzazione API non sa che quel campo lì non dovrebbe mai essere vuoto.
Tu sì. Allora codificalo.
Hai una pipeline di dati automatizzata e vuoi verificare se è davvero affidabile? Facciamo audit tecnici mirati — non rifacimenti completi quando non sono necessari. Contatta GDM-Pixel per una diagnosi onesta. Ti diremo cosa regge e cosa merita di essere blindato.






