




Die saubere Zeile, die ein schmutziges Problem verbirgt
Ein Kunde hat uns vor einigen Monaten kontaktiert. Er hatte einen Scraper aufgesetzt, um die Preise seiner Wettbewerber zu überwachen — etwa fünfzig Referenzen, nichts allzu Komplexes. Das Skript lief jede Nacht, die Daten landeten in einem Google Sheet, und alles schien perfekt.
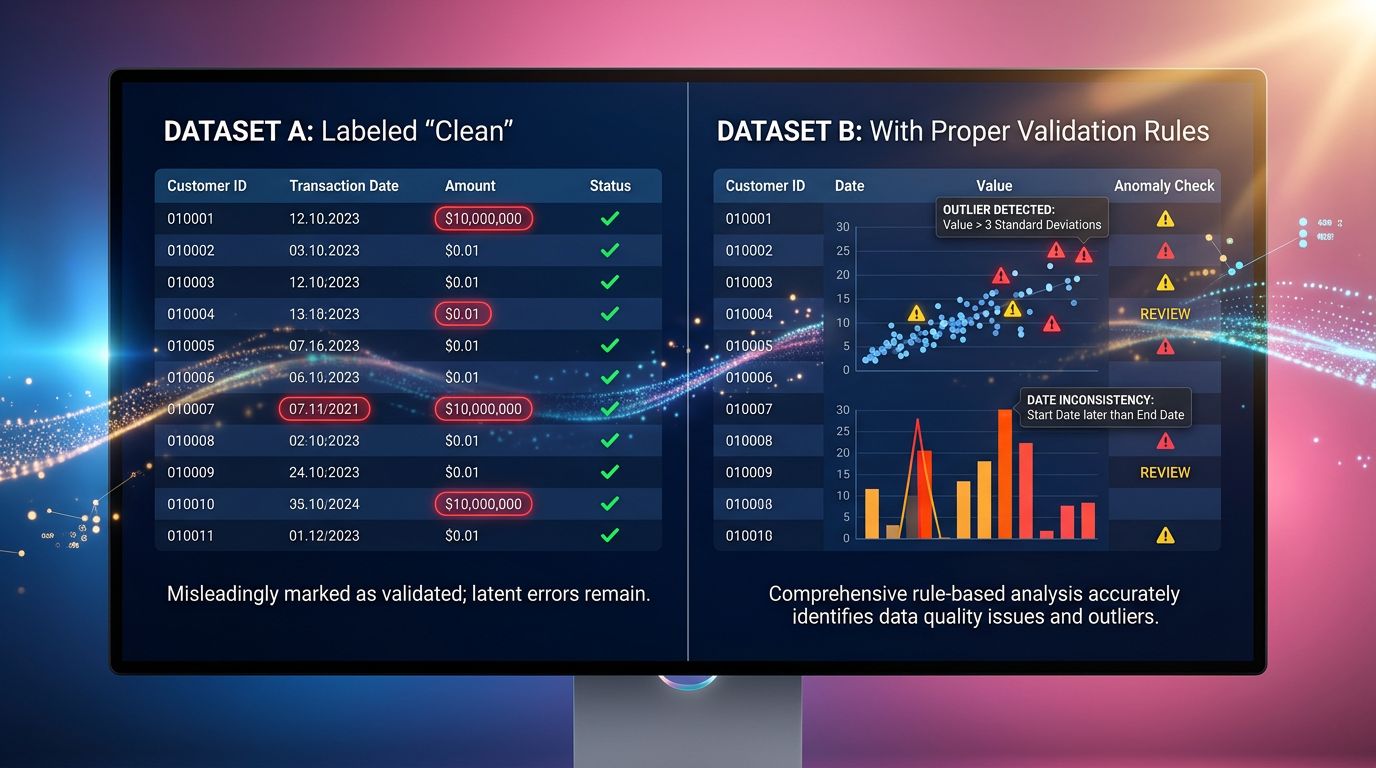
Gut gefüllte Zeilen. Keine Fehler. Kein leeres Feld.
Nur dass seine Preise seit drei Wochen systematisch unter Markt lagen. Er verlor Marge, ohne zu verstehen warum.
Der Scraper hatte die richtigen URLs abgerufen. Er hatte die richtigen CSS-Selektoren geparst. Er hatte saubere numerische Werte zurückgegeben. Und dennoch — er holte die Preise aus der gecachten Version der Wettbewerberseite, nicht die Echtzeit-Preise. Der Wettbewerber hatte seine clientseitige Rendering-Struktur geändert. Der Scraper hingegen hatte nichts gesehen.
Eine saubere Zeile bedeutet keine korrekte Zeile.
Das ist die Falle Nummer eins beim Daten-Scraping. Und wenn Sie Geschäftsentscheidungen auf Basis dieser Daten automatisieren — Preisgestaltung, Wettbewerbsbeobachtung, Bestandsverfolgung — fahren Sie vielleicht seit Wochen blind.
Warum Ihr Scraper Sie mit einem Lächeln belügt
Das Problem mit schlecht validierten Scrapern ist, dass sie nicht abstürzen. Sie liefern. Regelmäßig, sauber, ohne die geringste Exception zu werfen.
Hier sind die Szenarien, denen wir in unseren Audits am häufigsten begegnen:
Der CSS-Selektor, der den Tod des richtigen Inhalts überlebt. Die Zielseite hat ihr Template aktualisiert. Das alte div.price existiert noch — enthält aber jetzt einen Standardwert, einen Platzhalter, oder schlimmer, eine Null. Ihr Skript holt ihn ohne mit der Wimper zu zucken.
Das verzögerte JavaScript-Rendering. Immer mehr Seiten laden ihre Preise, Bestände oder Beschreibungen über asynchrone API-Aufrufe. Ein einfacher Scraper auf Basis von requests + BeautifulSoup holt das initiale HTML — bevor JavaScript Zeit hatte, die Felder zu befüllen. Ergebnis: leere Tags oder Fallback-Werte. Sauber. Falsch.
Der geolokalisierte oder personalisierte Inhalt. Die Seite erkennt Ihre IP, Ihren User-Agent oder das Fehlen eines Session-Cookies. Sie liefert Ihnen eine abgespeckte Version, eine Weiterleitungsseite oder ein anderes Angebot als das, was ein echter Kunde sieht. Ihr Scraper weiß nicht, dass er im Wartezimmer sitzt, während die echten Kunden schon am Tisch Platz genommen haben.
Das stille Rate-Limiting. Manche Seiten blockieren Ihren Scraper nicht — sie verlangsamen ihn und liefern ihm degradierte Daten. Kein 429-Fehler, kein Timeout. Nur ungefähre oder veraltete Werte. Unaufspürbar, wenn Sie den zurückgegebenen Inhalt nicht aktiv validieren.

Was “eine Zeile validieren” wirklich bedeutet
Datenvalidierung wird oft reduziert auf: “Ist das Feld leer?” Das ist notwendig. Das ist weit davon entfernt, ausreichend zu sein.
Hier ist, was eine ernsthafte Validierung abdecken muss:
Plausibilität prüfen, nicht nur Vorhandensein
Ein Preis von 0,00€ ist ein vorhandener Wert. Es ist auch ein absurder Wert für 99% der Kataloge. Ein Preis von 99999€ für ein Produkt, das letzte Woche 49€ wert war, verdient einen Flag, kein stilles Einfügen in die Datenbank.
Stellen Sie Geschäftsplausibilitätsregeln auf. Für einen E-Commerce-Katalog sieht das so aus:
- Preis > 0 und < max_Schwellenwert_Kategorie
- Abweichung vs vorheriger Wert < X% (Alarm bei Überschreitung)
- Einheit kohärent mit der Kategorie (keine Preise in Cent, wo Euro erwartet werden)
Das ist keine komplexe Entwicklung. Das ist Geschäftslogik, in Bedingungen übersetzt. Aber es setzt voraus, Ihre Daten zu kennen — und genau da scheitern viele Scraping-Projekte von Anfang an.
Den Seitenkontext kontrollieren, nicht nur das Zielfeld
Bevor Sie Ihren Zielwert extrahieren, prüfen Sie, dass Sie auf der richtigen Seite sind. Es klingt offensichtlich. In Produktion ist es das nicht.
Einige Checks, die systematisch integriert werden sollten:
- Stimmt der Seitentitel mit dem erwarteten Produkt überein?
- Ist der HTTP-Antwortcode wirklich ein 200 (und nicht ein als 200 getarnter Code, der eine personalisierte Fehlerseite verbirgt)?
- Entspricht die DOM-Struktur dem, was Sie erwarten — zumindest bei den strukturellen Elementen?
Eine Seite, die eine “Produkt nicht verfügbar”-Seite mit Status 200 und einem leeren Preisfeld auf 0 zurückgibt — Ihr einfacher Scraper wird das schlucken, ohne mit der Wimper zu zucken.
Daten mit Zeitstempel und Versionierung versehen
Jede extrahierte Zeile sollte einen Extraktions-Timestamp und idealerweise einen Hash des Rohinhalts der Seite mitführen. Warum?
Weil Sie, wenn Sie drei Wochen später eine Anomalie entdecken, wissen müssen, seit wann sie existiert. Und wenn die Seite ihre Struktur geändert hat, möchten Sie das HTML vor und nach vergleichen können.
Ohne Historie debuggen Sie blind. Mit einer auch nur minimalen Historie haben Sie einen Faden zum Ziehen.
Die wahren Kosten eines falschen Datums, das richtig erscheint
Zurück zu unserem Kunden. Drei Wochen unterausgerichtete Preise auf fünfzig Referenzen. Bei einigen margenstarken Referenzen lag die Abweichung bei 8 bis 12%.
Wir werden hier nicht die exakte Rechnung machen — diese Zahlen gehören ihm. Aber die Größenordnung sind mehrere tausend Euro verlorener Marge. Auf einer Datenpipeline, die einwandfrei lief, ohne jeden Alarm, ohne jedes Error-Log.
“Der schlimmste Bug ist nicht der, der Ihr System zum Absturz bringt. Es ist der, der es laufen lässt und Ihnen die Illusion gibt, dass alles in Ordnung ist.”
Das gilt für Scraping. Es gilt für jede automatisierte Datenpipeline — EDI-Flows, ERP-Synchronisation, Buchhaltungsexporte. Das still falsche Datum ist unendlich gefährlicher als der laute Fehler.
Einen lauten Fehler beheben Sie noch am selben Tag. Einen stillen Fehler entdecken Sie bei einem Audit, einer Bilanz, oder wenn ein Kunde Ihnen ein Problem meldet, das Sie seit Wochen hätten sehen müssen.
Wie wir einen Scraper bauen, der sich selbst misstraut
In unseren Automatisierungsprojekten — sei es für Wettbewerbsbeobachtung, Content-Aggregation oder Katalog-Synchronisation — haben wir gelernt, by-design paranoide Scraper zu bauen.
Hier sind die Prinzipien, die wir systematisch anwenden:
Extraktion von Validierung trennen
Niemals ein extrahiertes Datum direkt in die Datenbank oder einen Business-Flow einfügen. Immer eine Zwischen-Validierungsstufe durchlaufen — und sei sie minimal. Extraktion → Staging → Validierung → Produktion.
Einen “Datenvertrag” vor dem Codieren definieren
Bevor Sie die erste Zeile Code schreiben, dokumentieren Sie, was Sie erwarten: Typen, Formate, Wertebereiche, Abhängigkeiten zwischen Feldern. Dieser Vertrag wird zu Ihrer Validierungs-Spec. Wenn Ihre Daten den Vertrag nicht einhalten, kommen sie nicht durch.
Anomalien loggen, nicht nur Fehler
Ein null-Feld ist ein Fehler. Ein Preis von null bei einem aktiven Produkt ist eine Anomalie. Ein Preis, der über Nacht um 300% steigt, ist eine Anomalie. Ihre Logs müssen beide Ebenen erfassen — und Sie je nach Kritikalität unterschiedlich alarmieren.
Einen “Quarantäne”-Modus vorsehen
Zeilen, die die Validierung nicht bestehen, werden nicht gelöscht — sie werden mit dem Ablehnungsgrund in Quarantäne gestellt. Sie können sie so analysieren, verstehen, ob es ein Bug Ihres Scrapers oder eine echte Änderung auf Quellseite ist, und in voller Kenntnis entscheiden.
Mit bekannten Daten testen
Bevor Sie in Produktion deployen, testen Sie Ihren Scraper auf Seiten, deren exakte Werte Sie kennen. Vergleichen Sie das extrahierte Ergebnis mit dem erwarteten Wert. Das ist basic. Es wird oft ausgelassen. Und es ist das, was Ihnen erlaubt, JavaScript-Rendering- oder Personalisierungsprobleme zu erkennen, bevor sie in Produktion kommen.
Die drei Reflexe, die Sie ab sofort annehmen sollten
Wenn Sie eine automatisierte Datenpipeline in Produktion haben — Scraper, EDI-Flow, API-Synchronisation — hier ist, was ich Ihnen empfehle, diese Woche zu prüfen:
Reflex 1: Auditieren Sie Ihre historischen Daten. Nehmen Sie die letzten 30 Tage. Suchen Sie nach Nullwerten, identischen Werten in verdächtigen Zeiträumen, anormalen Trendbrüchen. Wenn Sie diesen Audit mangels Historie nicht machen können — das ist Ihre erste Baustelle.
Reflex 2: Fügen Sie eine Plausibilitätsregel auf Ihren kritischen Feldern hinzu. Nur eine. Die, die Ihre sensibelste Geschäftsentscheidung schützt. Preis, Bestand, Verfügbarkeitsstatus — wählen Sie und panzern Sie sie.
Reflex 3: Richten Sie einen Alarm auf anormale Variationen ein. Es braucht kein komplexes System. Ein einfaches Skript, das den Tageswert mit dem Median der letzten 7 Tage vergleicht und Ihnen eine Discord-Nachricht schickt, wenn die Abweichung einen Schwellenwert überschreitet. Wir haben das für mehrere Kunden in weniger als zwei Stunden eingerichtet.
Was sich konkret ändert
Ein Scraper, der sich selbst misstraut, das ist mehr Entwicklungszeit am Anfang. Es ist auch viel weniger Zeit, die damit verbracht wird, Anomalien in Produktion zu debuggen, einem Kunden zu erklären, warum seine Daten seit drei Wochen falsch waren, oder manuell wieder aufzubauen, was sauber hätte automatisiert werden sollen.
In unserer Agentur haben wir uns entschieden, diese Validierungsschichten ab der Designphase zu integrieren — nicht als Nachbesserung. Es verlängert die Specs um 20%. Es teilt die Produktionsvorfälle durch einen Faktor, den wir nicht mehr wirklich Lust haben zu berechnen.
Das saubere Datum ist eine Illusion, wenn Sie nicht selbst definieren, was “sauber” bedeutet.
Ihr Scraper weiß nicht, was ein kohärenter Preis für Ihren Katalog ist. Ihr EDI-Flow weiß nicht, dass ein negativer Bestand in Ihrem Geschäft unmöglich ist. Ihre API-Synchronisation weiß nicht, dass dieses bestimmte Feld nie leer sein dürfte.
Sie schon. Also kodieren Sie es.
Sie haben eine automatisierte Datenpipeline und möchten prüfen, ob sie wirklich zuverlässig ist? Wir machen gezielte technische Audits — keine kompletten Neugestaltungen, wenn sie nicht nötig sind. Kontaktieren Sie GDM-Pixel für eine ehrliche Diagnose. Wir sagen Ihnen, was hält und was gepanzert werden sollte.






