




Lo que nadie le dice sobre la optimización de LLMs
Ha desplegado un modelo de lenguaje. Funciona. Responde. Y sin embargo, tiene la sensación de estar dejando rendimiento sobre la mesa — velocidad de inferencia demasiado lenta, costes de cálculo que suben, calidad que llega a un techo.
No es un problema del modelo. Es un problema de optimización.
En los últimos meses, dos técnicas están recibiendo una atención creciente en los equipos de ingeniería de IA: el Multi-Token Prediction (MTP) y el Quantization-Aware Training (QAT). Por separado, cada una aporta ganancias medibles. Combinadas, cambian fundamentalmente la ecuación coste/rendimiento de un despliegue LLM.
Esto es lo que hemos observado, las cifras reales, y cómo decidir si vale la pena para su stack.
MTP: predecir varios tokens a la vez — por qué cambia todo
Un LLM estándar genera texto token a token. Un token a la vez, un pase forward a la vez. Este es el funcionamiento histórico de la arquitectura transformer — y también su principal cuello de botella en la inferencia.
El Multi-Token Prediction (MTP) rompe esta lógica secuencial. En lugar de predecir un único token siguiente, el modelo aprende a predecir varios tokens en paralelo durante el entrenamiento. En la práctica, se añaden “cabezas de predicción” adicionales a la arquitectura: una cabeza principal para el token N+1, una segunda para N+2, una tercera para N+3, etc.
Aquí es donde se vuelve interesante: estas cabezas adicionales solo están activas durante el entrenamiento. En la inferencia, el modelo puede utilizar una técnica de speculative decoding — genera varios tokens candidatos en paralelo, los verifica y valida o rechaza las predicciones siguientes en un solo paso.
Resultado concreto: una aceleración de la inferencia de 1,5x a 3x según los benchmarks, sin degradación medible en la calidad del texto generado.
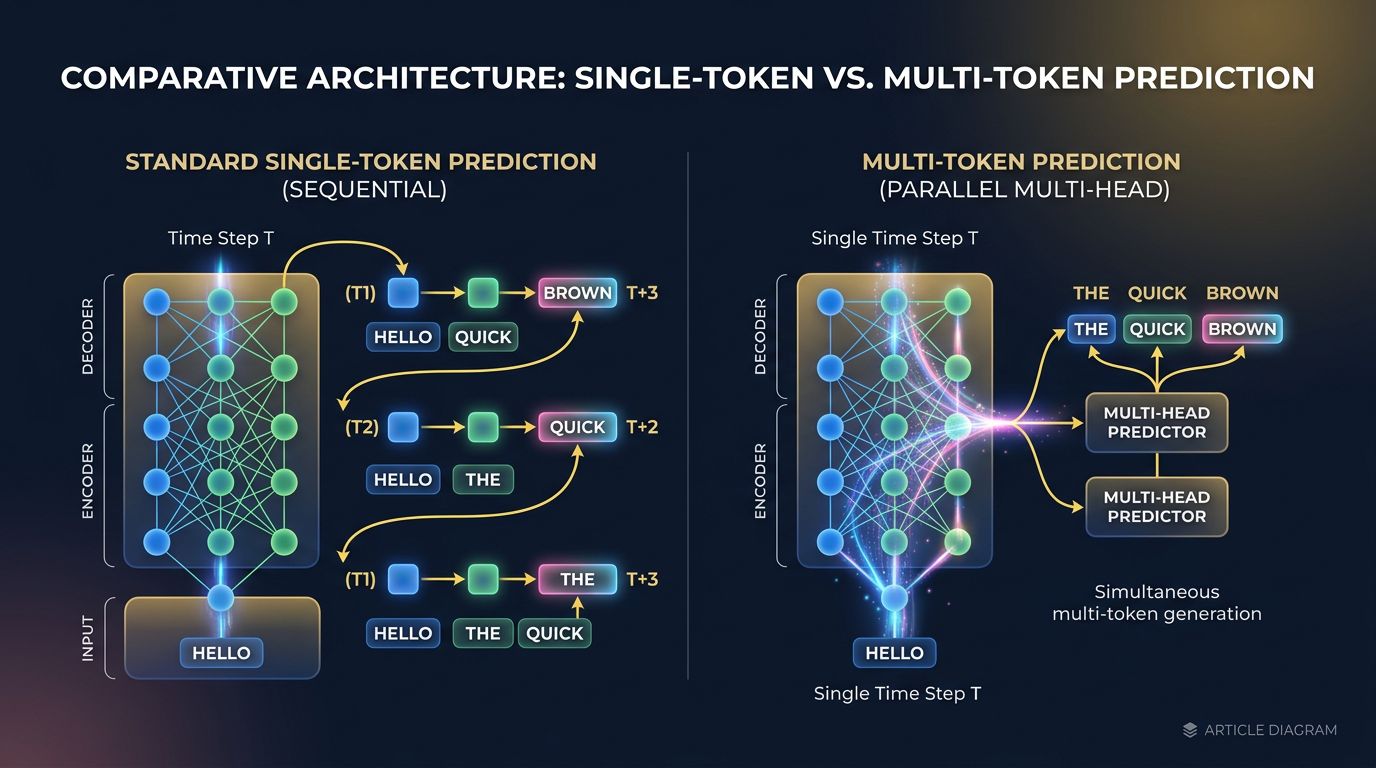
No es teoría. DeepSeek-V3 integró MTP en su arquitectura y publicó resultados documentados. Meta exploró enfoques similares en su investigación sobre LLaMA. El principio está validado a gran escala — y es el tipo de optimización que subyace a herramientas que usamos en producción, como Stellaris MCP para la búsqueda semántica de código.
QAT: la cuantización inteligente, no el compromiso habitual
La cuantización probablemente la conoce. Reducir la precisión de los pesos de un modelo (de float32 a int8, int4, o incluso menos) para disminuir el tamaño en memoria y acelerar los cálculos. Es una técnica ampliamente utilizada, especialmente mediante GGUF, GPTQ o AWQ.
El problema clásico: la cuantización post-entrenamiento degrada la calidad. Cuanto más agresivamente se cuantiza, más precisión se pierde en tareas complejas. Un modelo int4 post-training puede perder entre el 5 y el 15% de rendimiento en ciertos benchmarks de razonamiento.
El QAT — Quantization-Aware Training — resuelve este problema desde la raíz. En lugar de cuantizar a posteriori, se integra la restricción de cuantización durante el entrenamiento. El modelo aprende a ser robusto ante la precisión reducida. Se “acostumbra” a los redondeos y ajusta sus pesos en consecuencia.
“La cuantización post-entrenamiento es como fotografiar a alguien sin avisarle. El QAT es pedirle que pose.”
Las ganancias son significativas. En benchmarks publicados por varios equipos de investigación, un modelo entrenado con QAT en int4 supera sistemáticamente a su equivalente cuantizado en post-training — a veces incluso acercándose al rendimiento del modelo float16 original.
En términos prácticos: obtiene un modelo 4 veces más ligero, de 2x a 3x más rápido en la inferencia, con una degradación de calidad casi nula. Es la ecuación que todos buscaban.
Comparar las tres configuraciones: las cifras brutas
Esto es lo que muestran los benchmarks recientes al comparar los tres estados del mismo modelo base:
Configuración 1 — Modelo estándar (sin MTP, sin QAT)
Este es el punto de referencia. Precisión máxima, velocidad de inferencia limitada por la generación secuencial, alto coste de despliegue (GPU A100 o H100 requerida para modelos de 70B+). Calidad: 100% (referencia). Velocidad: 1x. Coste de memoria: 1x.
Configuración 2 — Modelo con MTP
La calidad permanece idéntica o ligeramente superior (el MTP obliga al modelo a desarrollar representaciones más ricas durante el entrenamiento). La velocidad de inferencia sube a 1,8x–2,5x según la longitud de las secuencias generadas. El coste de memoria permanece similar. Esta es la ganancia más limpia: no sacrifica nada, acelera.
Configuración 3 — Modelo con MTP + QAT
Aquí es donde las cifras se vuelven verdaderamente interesantes. Velocidad de inferencia: de 3x a 5x respecto al modelo base. Coste de memoria: dividido por 3 a 4. Calidad: 96–99% del modelo original según las tareas. Para la mayoría de los casos de uso reales (generación de contenido, clasificación, extracción de información), esta degradación del 1 al 4% es invisible en producción.
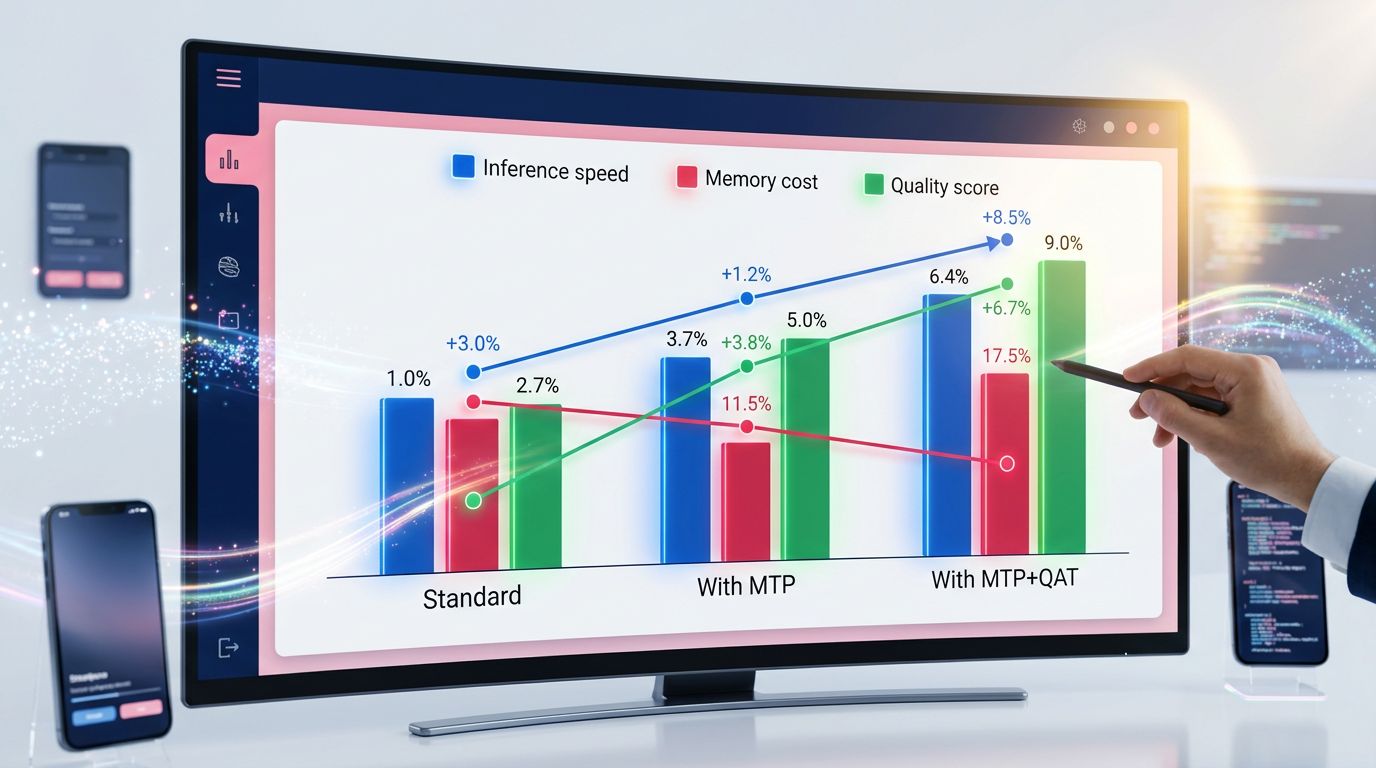
Lo que las agencias nunca dicen: la configuración MTP + QAT permite ejecutar un modelo de 70B en hardware diseñado para un 13B. Es un cambio de paradigma para los equipos que despliegan IA en producción con restricciones de hardware reales.
¿Cuándo vale la pena implementarlo?
Buena pregunta. Porque MTP y QAT no se improvisan. No son opciones que se marcan en una interfaz — son elecciones de arquitectura que se hacen durante el entrenamiento.
MTP vale la pena si:
- Entrena o hace fine-tuning de su propio modelo (tiene control sobre la arquitectura)
- Su caso de uso genera secuencias largas (resúmenes, redacción, código)
- La latencia de inferencia es un criterio crítico para su producto
QAT vale la pena si:
- Despliega en infraestructuras con restricciones (edge computing, servidores GPU de gama media)
- Su presupuesto de GPU es limitado y busca maximizar el throughput
- Ya ha probado la cuantización post-training y observado una degradación inaceptable
MTP + QAT juntos valen la pena si:
- Construye un producto IA en producción con SLA de rendimiento
- Quiere reducir sus costes de inferencia entre un 60 y un 75% sin rehacer su modelo desde cero
- Gestiona volúmenes importantes (miles de solicitudes por hora)
Si usa modelos mediante API (OpenAI, Anthropic, Mistral), estas optimizaciones ya están integradas en el lado del proveedor. No tiene que hacer nada — pero tampoco tiene el control.
Lo que esto cambia concretamente para una agencia o pyme tecnológica
En nuestro día a día en GDM-Pixel, usamos LLMs en producción — para Nova Mind, para la generación automatizada de contenido, para flujos de trabajo de clientes que ayudan a nuestros clientes a automatizar sus tareas repetitivas y ganar 10 horas a la semana. La cuestión de la optimización no es académica. Impacta directamente en nuestros costes y en nuestra capacidad para cumplir plazos.
Lo que vemos concretamente: los modelos open source recientes (DeepSeek, Llama 3, Mistral) integran cada vez más estas optimizaciones de forma nativa. Eligiendo bien su modelo base, ya se beneficia de parte de las ganancias sin tener que entrenar nada.
Para los equipos que hacen fine-tuning de sus propios modelos — y es una tendencia creciente entre las agencias tech y los editores de SaaS — integrar QAT desde el principio es una decisión que se toma una vez y que rinde frutos durante toda la vida útil del modelo.
“Optimizar a posteriori siempre cuesta más que optimizar desde el principio. Cierto para el código. Cierto para los modelos de IA.”
La verdadera pregunta no es “¿son útiles MTP y QAT?” — lo son, las cifras están ahí. La verdadera pregunta es: ¿en qué momento de su hoja de ruta de IA necesita este rendimiento?
Si está en fase de experimentación, trabaje con modelos cuantizados disponibles en Hugging Face. Si pasa a producción con restricciones de rendimiento, es el momento de ir más lejos.
Tres puntos a recordar antes de empezar
1. MTP acelera sin sacrificar calidad. Es la optimización más “limpia” — ganancias en inferencia, representaciones más ricas durante el entrenamiento, cero compromiso visible en producción.
2. QAT resuelve el problema que crea la cuantización clásica. Si ya rechazó la cuantización por la degradación de calidad, QAT merece una segunda oportunidad. Los modelos recientes entrenados con QAT en int4 aguantan la comparación frente a sus equivalentes float16.
3. La combinación MTP + QAT cambia la ecuación económica del despliegue de IA. Dividir el coste de memoria por 3 mientras se multiplica la velocidad de inferencia por 3 es la diferencia entre un proyecto de IA rentable y uno que sangra presupuesto de GPU.
Conclusión: la optimización de IA es ahora una ventaja competitiva
Hace dos años, estas técnicas estaban reservadas a los equipos de investigación de los grandes laboratorios. Hoy, son accesibles a cualquier equipo técnico motivado, documentadas en papers públicos, implementadas en frameworks open source.
Los equipos que las dominan hoy despliegan más rápido, a menor coste, con mejores rendimientos. Los demás pagan facturas de GPU que no tienen razón de ser tan altas.
En GDM-Pixel, documentamos lo que hacemos realmente en producción — no lo que podríamos hacer teóricamente. Si está construyendo un producto de IA y tiene preguntas sobre su arquitectura de optimización, nuestro acompañamiento de agencia IA siempre parte de su stack real — podemos analizarlo juntos y decirle honestamente dónde están las ganancias más rápidas de conseguir.
Sin consultoría mágica. Solo experiencia en campo sobre lo que realmente funciona.






