




What nobody tells you about LLM optimization
You’ve deployed a language model. It runs. It responds. And yet you feel like you’re leaving performance on the table — inference speed too slow, compute costs climbing, quality hitting a ceiling.
This isn’t a model problem. It’s an optimization problem.
Over the past few months, two techniques have been receiving growing attention in AI engineering teams: Multi-Token Prediction (MTP) and Quantization-Aware Training (QAT). Separately, each delivers measurable gains. Combined, they fundamentally change the cost/performance equation of an LLM deployment.
Here’s what we’ve observed, the real numbers, and how to decide whether it’s worth it for your stack.
MTP: predicting multiple tokens at once — why it changes everything
A standard LLM generates text token by token. One token at a time, one forward pass at a time. This is the historical behavior of the transformer architecture — and also its main bottleneck at inference.
Multi-Token Prediction (MTP) breaks this sequential logic. Instead of predicting a single next token, the model learns to predict multiple tokens in parallel during training. In practice, additional “prediction heads” are added to the architecture: a main head for token N+1, a second for N+2, a third for N+3, and so on.
Here’s where it gets interesting: these extra heads are only active during training. At inference, the model can use a speculative decoding technique — it generates several candidate tokens in parallel, verifies them, and validates or rejects subsequent predictions in a single pass.
Concrete result: an inference speedup of 1.5x to 3x according to benchmarks, with no measurable degradation in the quality of generated text.
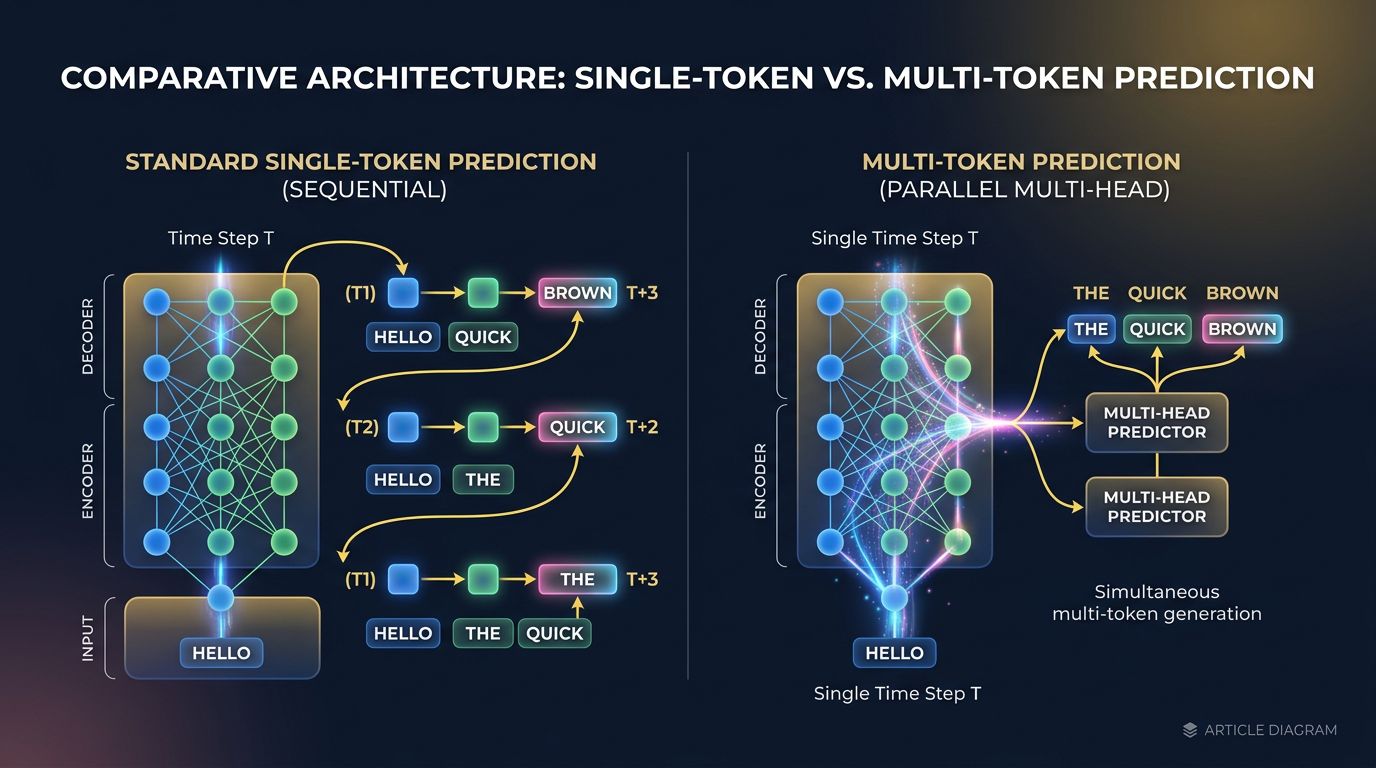
This isn’t theory. DeepSeek-V3 integrated MTP into its architecture and published documented results. Meta explored similar approaches in its LLaMA research. The principle is validated at scale — and it’s the kind of optimization that underpins tools we use in production, like Stellaris MCP for semantic code search.
QAT: intelligent quantization, not the usual compromise
You’re probably familiar with quantization. Reducing the precision of a model’s weights (from float32 to int8, int4, or even less) to decrease memory footprint and speed up computations. It’s a widespread technique, used notably via GGUF, GPTQ, or AWQ.
The classic problem: post-training quantization degrades quality. The more aggressively you quantize, the more precision you lose on complex tasks. An int4 post-training model can lose 5 to 15% of performance on certain reasoning benchmarks.
QAT — Quantization-Aware Training — solves this problem at the root. Instead of quantizing after the fact, the quantization constraint is integrated during training. The model learns to be robust to reduced precision. It “gets used to” rounding and adjusts its weights accordingly.
“Post-training quantization is like photographing someone without warning them. QAT is asking them to pose.”
The gains are significant. On benchmarks published by several research teams, a model trained with int4 QAT consistently outperforms its post-training quantized equivalent — sometimes even approaching the performance of the original float16 model.
In practical terms: you get a model that is 4x lighter, 2x to 3x faster at inference, with near-zero quality degradation. That’s the equation everyone was looking for.
Comparing the three configurations: the raw numbers
Here’s what recent benchmarks show when comparing the three states of the same base model:
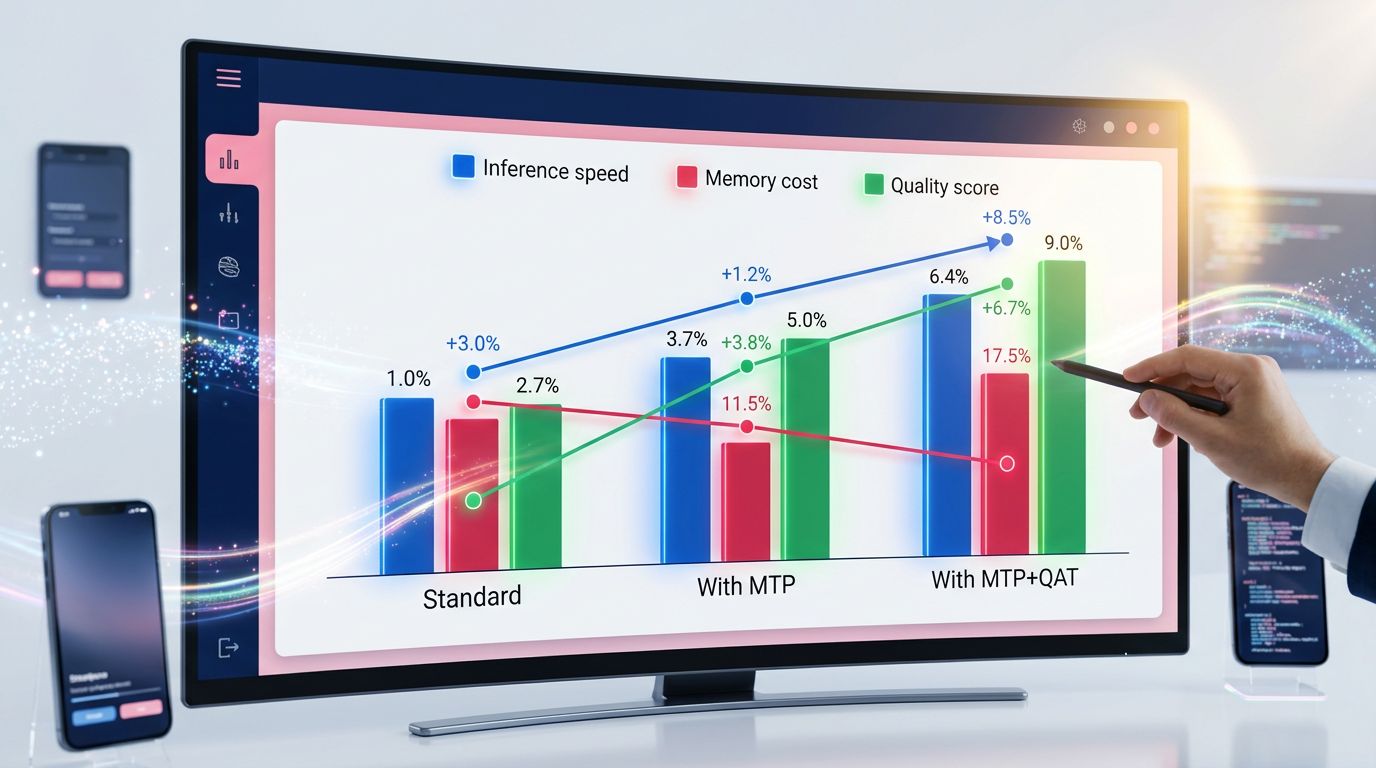
Configuration 1 — Standard model (no MTP, no QAT)
This is the baseline. Maximum precision, inference speed limited by sequential generation, high deployment cost (A100 or H100 GPU required for 70B+ models). Quality: 100% (reference). Speed: 1x. Memory cost: 1x.
Configuration 2 — Model with MTP
Quality remains identical or slightly superior (MTP forces the model to develop richer representations during training). Inference speed rises to 1.8x–2.5x depending on the length of generated sequences. Memory cost remains similar. This is the cleanest gain: you sacrifice nothing, you accelerate.
Configuration 3 — Model with MTP + QAT
This is where the numbers get truly interesting. Inference speed: 3x to 5x compared to the base model. Memory cost: divided by 3 to 4. Quality: 96–99% of the original model depending on the task. For most real-world use cases (content generation, classification, information extraction), this 1 to 4% degradation is invisible in production.
What agencies never tell you: the MTP + QAT configuration allows you to run a 70B model on hardware designed for a 13B. This is a paradigm shift for teams deploying AI in production with real hardware constraints.
When is it worth implementing?
Good question. Because MTP and QAT don’t just happen. They’re not options you check in an interface — they’re architectural choices made at training time.
MTP is worth it if:
- You’re training or fine-tuning your own model (you have control over the architecture)
- Your use case generates long sequences (summaries, writing, code)
- Inference latency is a critical criterion for your product
QAT is worth it if:
- You’re deploying on constrained infrastructures (edge computing, mid-range GPU servers)
- Your GPU budget is limited and you’re looking to maximize throughput
- You’ve already tried post-training quantization and observed unacceptable degradation
MTP + QAT together is worth it if:
- You’re building a production AI product with performance SLAs
- You want to reduce your inference costs by 60 to 75% without rebuilding your model from scratch
- You handle significant volumes (thousands of requests per hour)
If you’re using models via API (OpenAI, Anthropic, Mistral), these optimizations are already integrated on the provider side. You don’t need to do anything — but you also don’t have control.
What this concretely changes for an agency or tech SME
In our day-to-day work at GDM-Pixel, we use LLMs in production — for Nova Mind, for automated content generation, for client workflows that help our clients automate their repetitive tasks and gain 10 hours per week. The optimization question isn’t academic. It directly impacts our costs and our ability to meet deadlines.
What we see concretely: recent open source models (DeepSeek, Llama 3, Mistral) increasingly integrate these optimizations natively. By choosing your base model wisely, you already benefit from part of the gains without having to train anything.
For teams fine-tuning their own models — and this is a growing trend among tech agencies and SaaS publishers — integrating QAT from the start is a decision made once that pays off for the entire lifetime of the model.
“Optimizing after the fact always costs more than optimizing from the start. True for code. True for AI models.”
The real question isn’t “are MTP and QAT useful?” — they are, the numbers are there. The real question is: at what point in your AI roadmap do you need this performance?
If you’re in the experimentation phase, work with quantized models available on Hugging Face. If you’re moving to production with performance constraints, it’s time to go further.
Three points to remember before you start
1. MTP accelerates without sacrificing quality. It’s the “cleanest” optimization — inference gains, richer representations during training, zero visible compromise in production.
2. QAT solves the problem that classical quantization creates. If you’ve already rejected quantization because of quality degradation, QAT deserves a second look. Recent models trained with int4 QAT hold their own against their float16 equivalents.
3. The MTP + QAT combination changes the economic equation of AI deployment. Dividing memory cost by 3 while multiplying inference speed by 3 is the difference between a profitable AI project and one that bleeds GPU budget.
Conclusion: AI optimization is now a competitive advantage
Two years ago, these techniques were reserved for the research teams of major labs. Today, they’re accessible to any motivated technical team, documented in public papers, implemented in open source frameworks.
The teams that master them today deploy faster, at lower cost, with better performance. The others pay GPU bills that have no reason to be that high.
At GDM-Pixel, we document what we actually do in production — not what we could theoretically do. If you’re building an AI product and have questions about your optimization architecture, our AI agency support always starts from your real stack — we can look at it together and tell you honestly where the fastest gains are to be found.
No magic consulting. Just field experience on what actually works.






