




Was niemand Ihnen über die Optimierung von LLMs erzählt
Sie haben ein Sprachmodell deployed. Es läuft. Es antwortet. Und dennoch haben Sie das Gefühl, Leistung auf dem Tisch liegen zu lassen — Inferenzgeschwindigkeit zu langsam, Rechenkosten steigen, Qualität stagniert.
Das ist kein Modellproblem. Es ist ein Optimierungsproblem.
In den letzten Monaten erhalten zwei Techniken in KI-Engineering-Teams wachsende Aufmerksamkeit: Multi-Token Prediction (MTP) und Quantization-Aware Training (QAT). Einzeln bringt jede messbare Gewinne. Kombiniert verändern sie grundlegend die Kosten-Leistungs-Gleichung eines LLM-Deployments.
Hier ist, was wir beobachtet haben, die realen Zahlen und wie Sie entscheiden, ob es sich für Ihren Stack lohnt.
MTP: mehrere Tokens gleichzeitig vorhersagen — warum das alles ändert
Ein Standard-LLM generiert Text Token für Token. Ein Token auf einmal, ein Forward-Pass auf einmal. Das ist das historische Verhalten der Transformer-Architektur — und auch ihr Hauptengpass bei der Inferenz.
Multi-Token Prediction (MTP) bricht diese sequenzielle Logik. Anstatt nur das nächste einzelne Token vorherzusagen, lernt das Modell, beim Training mehrere Tokens parallel vorherzusagen. In der Praxis werden der Architektur zusätzliche “Prediction Heads” hinzugefügt: ein Hauptkopf für Token N+1, ein zweiter für N+2, ein dritter für N+3 usw.
Hier wird es interessant: Diese zusätzlichen Köpfe sind nur während des Trainings aktiv. Bei der Inferenz kann das Modell eine Technik des Speculative Decodings nutzen — es generiert mehrere Kandidaten-Tokens parallel, überprüft sie und validiert oder verwirft die folgenden Vorhersagen in einem einzigen Durchlauf.
Konkretes Ergebnis: eine Beschleunigung der Inferenz um das 1,5- bis 3-Fache laut Benchmarks, ohne messbare Verschlechterung der Qualität des generierten Textes.
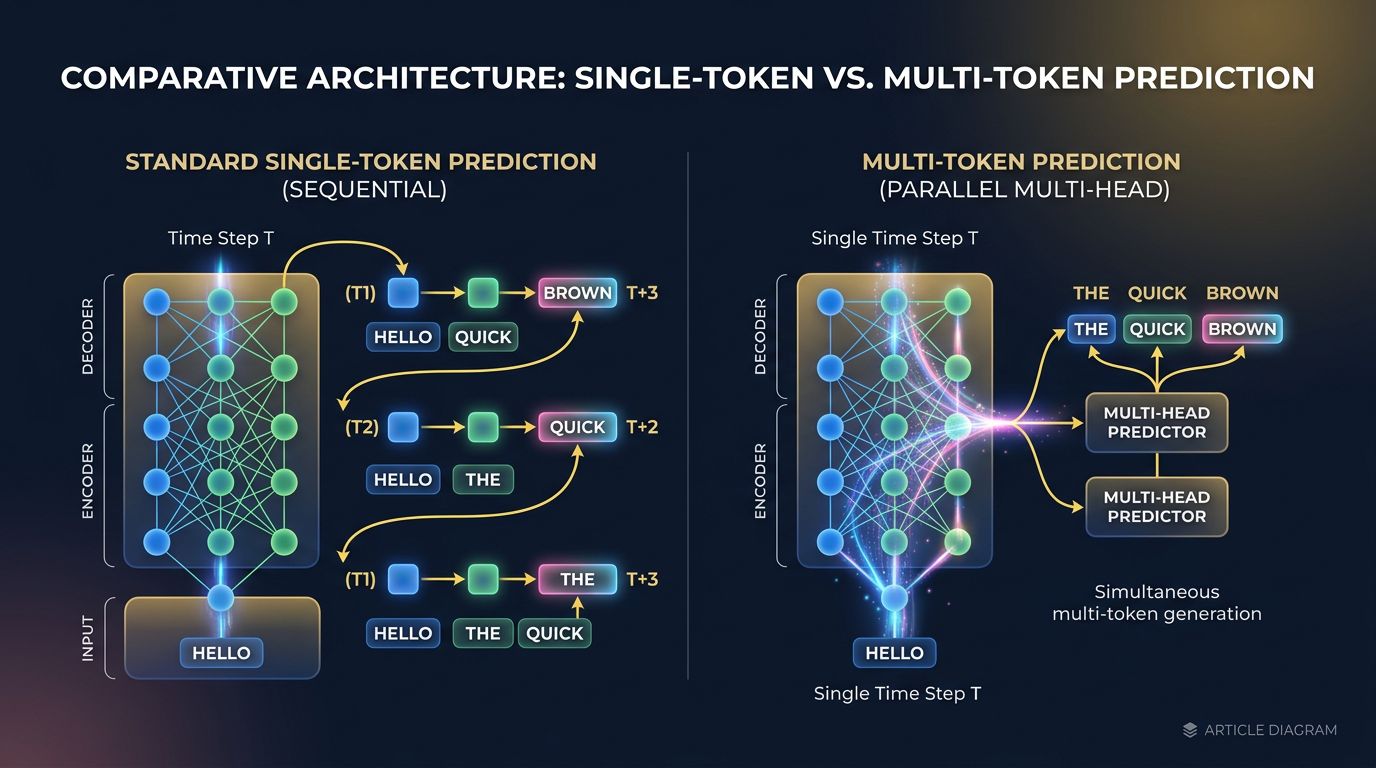
Das ist keine Theorie. DeepSeek-V3 hat MTP in seine Architektur integriert und dokumentierte Ergebnisse veröffentlicht. Meta hat ähnliche Ansätze in seiner LLaMA-Forschung untersucht. Das Prinzip ist in großem Maßstab validiert — und es ist die Art von Optimierung, die Tools zugrunde liegt, die wir in der Produktion verwenden, wie Stellaris MCP für die semantische Codesuche.
QAT: intelligente Quantisierung, nicht der übliche Kompromiss
Quantisierung kennen Sie wahrscheinlich. Die Präzision der Gewichte eines Modells reduzieren (von float32 auf int8, int4 oder sogar weniger), um den Speicherbedarf zu verringern und Berechnungen zu beschleunigen. Es ist eine weit verbreitete Technik, die insbesondere über GGUF, GPTQ oder AWQ eingesetzt wird.
Das klassische Problem: Post-Training-Quantisierung verschlechtert die Qualität. Je aggressiver man quantisiert, desto mehr Präzision verliert man bei komplexen Aufgaben. Ein int4-Modell nach Post-Training kann bei bestimmten Reasoning-Benchmarks 5 bis 15% Leistung verlieren.
QAT — Quantization-Aware Training — löst dieses Problem an der Wurzel. Anstatt nachträglich zu quantisieren, wird die Quantisierungseinschränkung während des Trainings integriert. Das Modell lernt, robust gegenüber reduzierter Präzision zu sein. Es “gewöhnt sich” an die Rundungen und passt seine Gewichte entsprechend an.
“Post-Training-Quantisierung ist wie jemanden zu fotografieren, ohne ihn zu warnen. QAT ist, ihn um eine Pose zu bitten.”
Die Gewinne sind erheblich. In Benchmarks, die von mehreren Forschungsteams veröffentlicht wurden, übertrifft ein mit int4-QAT trainiertes Modell systematisch sein post-training-quantisiertes Äquivalent — manchmal nähert es sich sogar den Leistungen des originalen float16-Modells an.
In praktischen Begriffen: Sie erhalten ein Modell, das 4-mal leichter, 2- bis 3-mal schneller bei der Inferenz ist, mit nahezu keiner Qualitätsverschlechterung. Das ist die Gleichung, die alle gesucht haben.
Die drei Konfigurationen im Vergleich: die rohen Zahlen
Hier ist, was aktuelle Benchmarks zeigen, wenn man die drei Zustände desselben Basismodells vergleicht:
Konfiguration 1 — Standardmodell (ohne MTP, ohne QAT)
Dies ist der Ausgangspunkt. Maximale Präzision, Inferenzgeschwindigkeit begrenzt durch sequenzielle Generierung, hohe Deployment-Kosten (A100- oder H100-GPU für 70B+-Modelle erforderlich). Qualität: 100% (Referenz). Geschwindigkeit: 1x. Speicherkosten: 1x.
Konfiguration 2 — Modell mit MTP
Die Qualität bleibt identisch oder leicht überlegen (MTP zwingt das Modell, während des Trainings reichhaltigere Repräsentationen zu entwickeln). Die Inferenzgeschwindigkeit steigt je nach Länge der generierten Sequenzen auf 1,8x–2,5x. Die Speicherkosten bleiben ähnlich. Das ist der sauberste Gewinn: Sie opfern nichts, Sie beschleunigen.
Konfiguration 3 — Modell mit MTP + QAT
Hier werden die Zahlen wirklich interessant. Inferenzgeschwindigkeit: 3x bis 5x im Vergleich zum Basismodell. Speicherkosten: geteilt durch 3 bis 4. Qualität: 96–99% des Originalmodells je nach Aufgabe. Für die meisten realen Anwendungsfälle (Inhaltsgenerierung, Klassifikation, Informationsextraktion) ist diese Verschlechterung von 1 bis 4% in der Produktion unsichtbar.
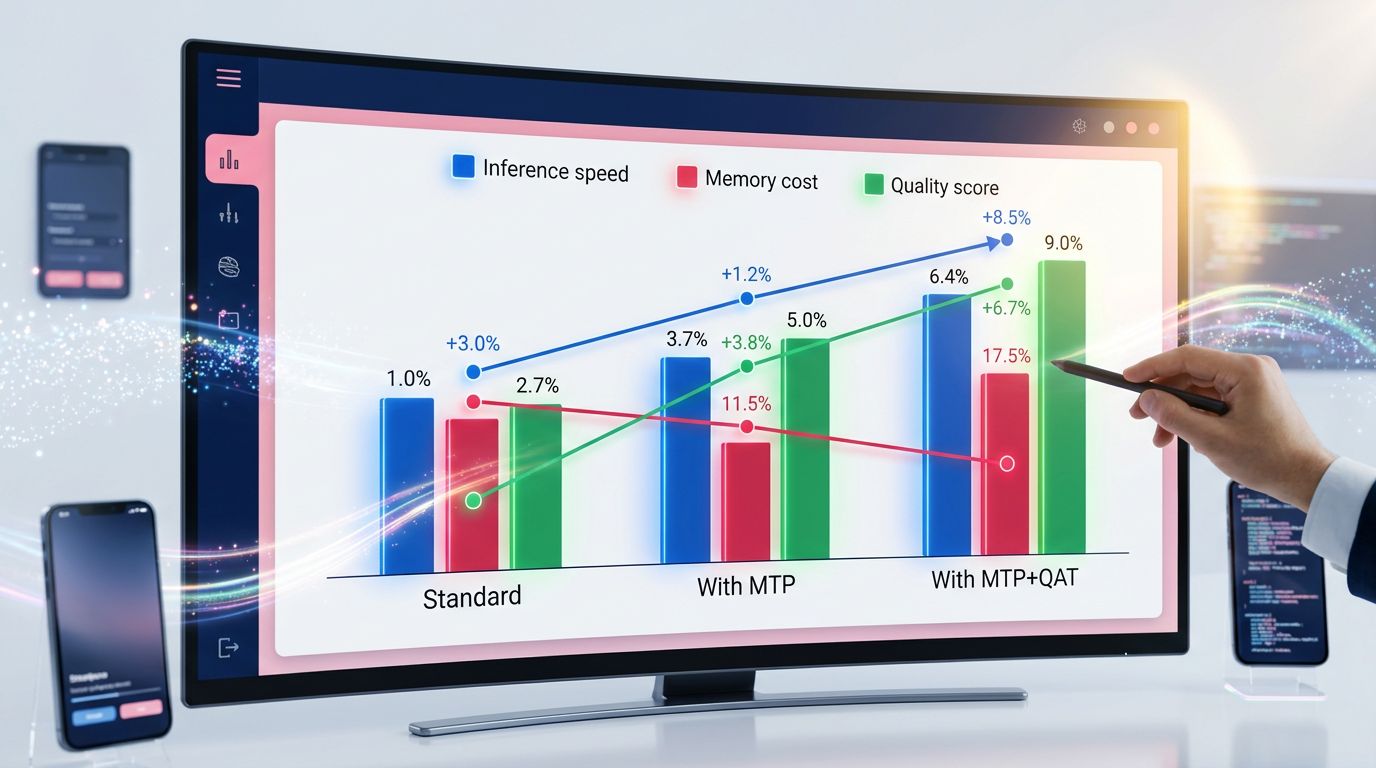
Was Agenturen Ihnen nie sagen: Die MTP + QAT-Konfiguration erlaubt es, ein 70B-Modell auf Hardware auszuführen, die für ein 13B ausgelegt ist. Das ist ein Paradigmenwechsel für Teams, die KI in der Produktion mit echten Hardware-Einschränkungen einsetzen.
Wann lohnt sich die Implementierung?
Gute Frage. Denn MTP und QAT werden nicht improvisiert. Es sind keine Optionen, die man in einer Benutzeroberfläche ankreuzt — es sind Architekturentscheidungen, die beim Training getroffen werden.
MTP lohnt sich, wenn:
- Sie Ihr eigenes Modell trainieren oder fine-tunen (Sie haben Kontrolle über die Architektur)
- Ihr Anwendungsfall lange Sequenzen generiert (Zusammenfassungen, Texterstellung, Code)
- Inferenzlatenz ein kritisches Kriterium für Ihr Produkt ist
QAT lohnt sich, wenn:
- Sie auf eingeschränkten Infrastrukturen deployen (Edge Computing, Mid-Range-GPU-Server)
- Ihr GPU-Budget begrenzt ist und Sie den Durchsatz maximieren möchten
- Sie bereits Post-Training-Quantisierung ausprobiert und eine inakzeptable Verschlechterung beobachtet haben
MTP + QAT zusammen lohnt sich, wenn:
- Sie ein KI-Produkt in der Produktion mit Performance-SLAs aufbauen
- Sie Ihre Inferenzkosten um 60 bis 75% senken möchten, ohne Ihr Modell von Grund auf neu zu erstellen
- Sie hohe Volumen verwalten (Tausende von Anfragen pro Stunde)
Wenn Sie Modelle über API (OpenAI, Anthropic, Mistral) verwenden, sind diese Optimierungen bereits anbieterseitig integriert. Sie müssen nichts tun — aber Sie haben auch keine Kontrolle.
Was das konkret für eine Agentur oder ein Tech-KMU ändert
In unserem täglichen Betrieb bei GDM-Pixel setzen wir LLMs in der Produktion ein — für Nova Mind, für automatisierte Inhaltsgenerierung, für Kunden-Workflows, die unseren Kunden helfen, ihre wiederkehrenden Aufgaben zu automatisieren und 10 Stunden pro Woche zu gewinnen. Die Optimierungsfrage ist nicht akademisch. Sie wirkt sich direkt auf unsere Kosten und unsere Fähigkeit aus, Termine einzuhalten.
Was wir konkret sehen: Neuere Open-Source-Modelle (DeepSeek, Llama 3, Mistral) integrieren diese Optimierungen zunehmend nativ. Durch die richtige Wahl Ihres Basismodells profitieren Sie bereits von einem Teil der Gewinne, ohne etwas trainieren zu müssen.
Für Teams, die ihre eigenen Modelle fine-tunen — und das ist ein wachsender Trend bei Tech-Agenturen und SaaS-Herausgebern — ist die Integration von QAT von Anfang an eine Entscheidung, die einmal getroffen wird und sich über die gesamte Lebensdauer des Modells auszahlt.
“Nachträglich zu optimieren kostet immer mehr als von Anfang an zu optimieren. Wahr für Code. Wahr für KI-Modelle.”
Die eigentliche Frage ist nicht “Sind MTP und QAT nützlich?” — das sind sie, die Zahlen sind da. Die eigentliche Frage lautet: An welchem Punkt Ihrer KI-Roadmap benötigen Sie diese Leistung?
Wenn Sie sich in der Experimentierphase befinden, arbeiten Sie mit quantisierten Modellen, die auf Hugging Face verfügbar sind. Wenn Sie mit Leistungsanforderungen in die Produktion übergehen, ist es Zeit, weiter zu gehen.
Drei Punkte, die Sie sich vor dem Start merken sollten
1. MTP beschleunigt ohne Qualitätseinbußen. Das ist die “sauberste” Optimierung — Inferenzgewinne, reichhaltigere Repräsentationen beim Training, kein sichtbarer Kompromiss in der Produktion.
2. QAT löst das Problem, das klassische Quantisierung erzeugt. Wenn Sie Quantisierung bereits wegen Qualitätsverschlechterung abgelehnt haben, verdient QAT einen zweiten Blick. Neuere Modelle, die mit int4-QAT trainiert wurden, halten dem Vergleich mit ihren float16-Äquivalenten stand.
3. Die Kombination MTP + QAT ändert die wirtschaftliche Gleichung des KI-Deployments. Die Speicherkosten durch 3 zu teilen und gleichzeitig die Inferenzgeschwindigkeit mit 3 zu multiplizieren ist der Unterschied zwischen einem profitablen KI-Projekt und einem, das das GPU-Budget aufzehrt.
Fazit: KI-Optimierung ist jetzt ein Wettbewerbsvorteil
Vor zwei Jahren waren diese Techniken den Forschungsteams der großen Labore vorbehalten. Heute sind sie für jedes motivierte technische Team zugänglich, in öffentlichen Papers dokumentiert, in Open-Source-Frameworks implementiert.
Die Teams, die sie heute beherrschen, deployen schneller, zu geringeren Kosten, mit besserer Leistung. Die anderen zahlen GPU-Rechnungen, die keinen Grund haben, so hoch zu sein.
Bei GDM-Pixel dokumentieren wir, was wir wirklich in der Produktion tun — nicht was wir theoretisch tun könnten. Wenn Sie ein KI-Produkt aufbauen und Fragen zu Ihrer Optimierungsarchitektur haben, geht unsere KI-Agentur-Begleitung immer von Ihrem realen Stack aus — wir können ihn gemeinsam analysieren und Ihnen ehrlich sagen, wo die schnellsten Gewinne zu holen sind.
Kein magisches Consulting. Nur Felderfahrung über das, was wirklich funktioniert.






