




Ce que personne ne vous dit sur l’optimisation des LLMs
Vous avez déployé un modèle de langage. Il tourne. Il répond. Et pourtant, vous avez l’impression de laisser des performances sur la table — vitesse d’inférence trop lente, coûts de calcul qui grimpent, qualité qui plafonne.
Ce n’est pas un problème de modèle. C’est un problème d’optimisation.
Depuis quelques mois, deux techniques font l’objet d’une attention croissante dans les équipes d’ingénierie IA : le Multi-Token Prediction (MTP) et le Quantization-Aware Training (QAT). Séparément, chacune apporte des gains mesurables. Combinées, elles changent fondamentalement l’équation coût/performance d’un déploiement LLM.
Voici ce qu’on a observé, les chiffres réels, et comment décider si ça vaut le coup pour votre stack.
MTP : prédire plusieurs tokens à la fois, pourquoi ça change tout
Un LLM standard génère du texte token par token. Un token à la fois, une passe forward à la fois. C’est le fonctionnement historique de l’architecture transformer — et c’est aussi son principal goulot d’étranglement à l’inférence.
Le Multi-Token Prediction (MTP) casse cette logique séquentielle. Au lieu de prédire un seul token suivant, le modèle apprend à prédire plusieurs tokens en parallèle lors de l’entraînement. En pratique, on ajoute des “têtes de prédiction” supplémentaires sur l’architecture : une tête principale pour le token N+1, une seconde pour N+2, une troisième pour N+3, etc.
Voici où ça devient intéressant : ces têtes supplémentaires ne sont actives qu’à l’entraînement. À l’inférence, le modèle peut utiliser une technique de speculative decoding — il génère plusieurs tokens candidats en parallèle, les vérifie, et valide ou rejette les prédictions suivantes en un seul passage.
Résultat concret : une accélération de l’inférence de 1,5x à 3x selon les benchmarks, sans dégradation mesurable de la qualité du texte généré.
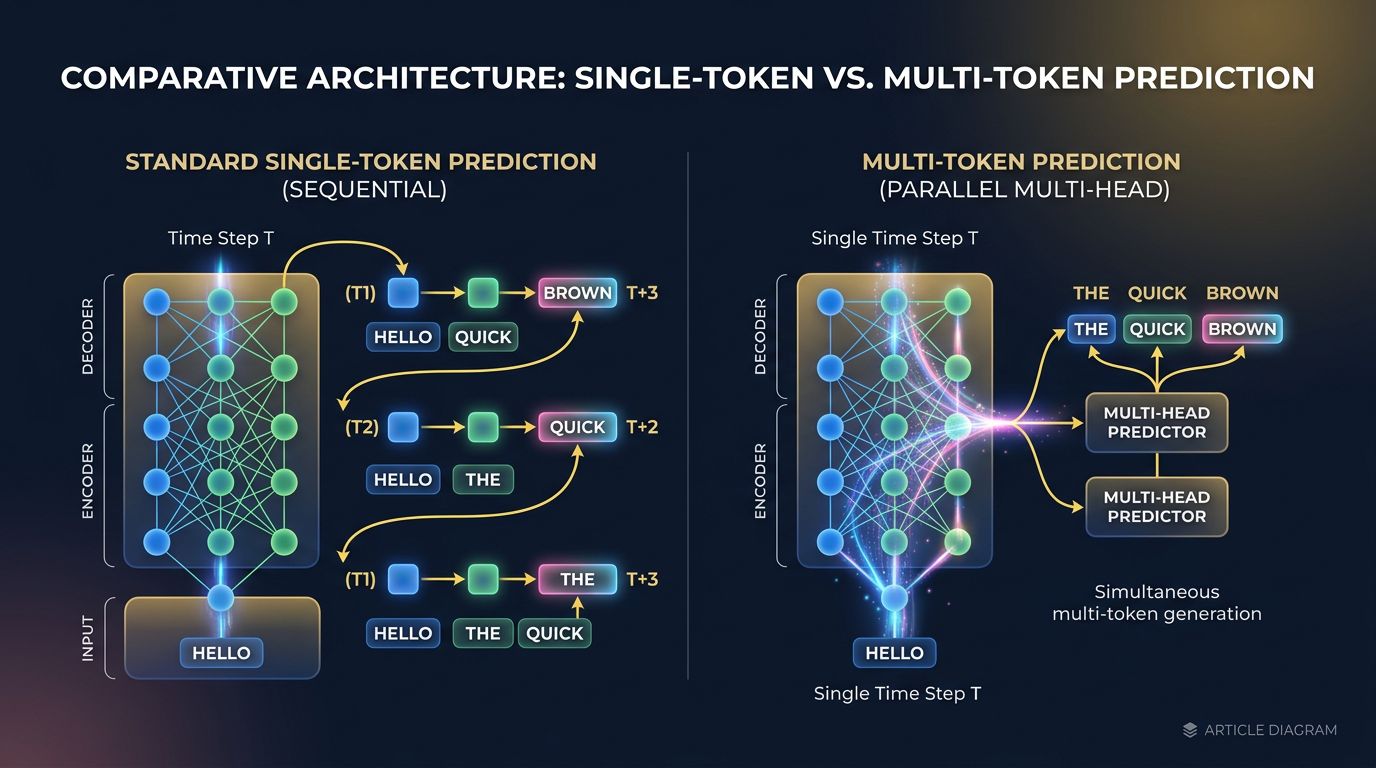
Ce n’est pas de la théorie. DeepSeek-V3 a intégré MTP dans son architecture et publié des résultats documentés. Meta a exploré des approches similaires dans ses recherches sur LLaMA. Le principe est validé à grande échelle — et c’est le genre d’optimisation qui sous-tend des outils que nous utilisons en production, comme Stellaris MCP pour la recherche sémantique de code.
QAT : la quantification intelligente, pas le compromis habituel
La quantification, vous connaissez probablement. Réduire la précision des poids d’un modèle (de float32 vers int8, int4, voire moins) pour diminuer la taille en mémoire et accélérer les calculs. C’est une technique répandue, utilisée notamment via GGUF, GPTQ ou AWQ.
Le problème classique : la quantification post-entraînement dégrade la qualité. Plus on quantifie agressivement, plus on perd en précision sur les tâches complexes. Un modèle en int4 post-training peut perdre 5 à 15% de performance sur certains benchmarks de raisonnement.
Le QAT — Quantization-Aware Training — résout ce problème à la racine. Au lieu de quantifier après coup, on intègre la contrainte de quantification pendant l’entraînement. Le modèle apprend à être robuste à la précision réduite. Il “s’habitue” aux arrondis et ajuste ses poids en conséquence.
“La quantification post-entraînement, c’est comme photographier quelqu’un sans le prévenir. Le QAT, c’est lui demander de poser.”
Les gains sont significatifs. Sur les benchmarks publiés par plusieurs équipes de recherche, un modèle entraîné avec QAT en int4 surpasse systématiquement son équivalent quantifié en post-training — parfois même en se rapprochant des performances du modèle float16 original.
En termes pratiques : vous obtenez un modèle 4x plus léger, 2x à 3x plus rapide à l’inférence, avec une dégradation de qualité quasi nulle. C’est l’équation que tout le monde cherchait.
Comparer les trois configurations : les chiffres bruts
Voici ce que les benchmarks récents montrent quand on compare les trois états d’un même modèle de base :
Configuration 1 — Modèle standard (sans MTP, sans QAT)
C’est le point de référence. Précision maximale, vitesse d’inférence limitée par la génération séquentielle, coût de déploiement élevé (GPU A100 ou H100 requis pour les modèles 70B+). Qualité : 100% (référence). Vitesse : 1x. Coût mémoire : 1x.
Configuration 2 — Modèle avec MTP
La qualité reste identique ou légèrement supérieure (le MTP force le modèle à développer des représentations plus riches lors de l’entraînement). La vitesse d’inférence monte à 1,8x–2,5x selon la longueur des séquences générées. Le coût mémoire reste similaire. C’est le gain le plus propre : vous ne sacrifiez rien, vous accélérez.
Configuration 3 — Modèle avec MTP + QAT
C’est là que les chiffres deviennent vraiment intéressants. Vitesse d’inférence : 3x à 5x par rapport au modèle de base. Coût mémoire : divisé par 3 à 4. Qualité : 96–99% du modèle original selon les tâches. Pour la plupart des cas d’usage réels (génération de contenu, classification, extraction d’information), cette dégradation de 1 à 4% est invisible en production.
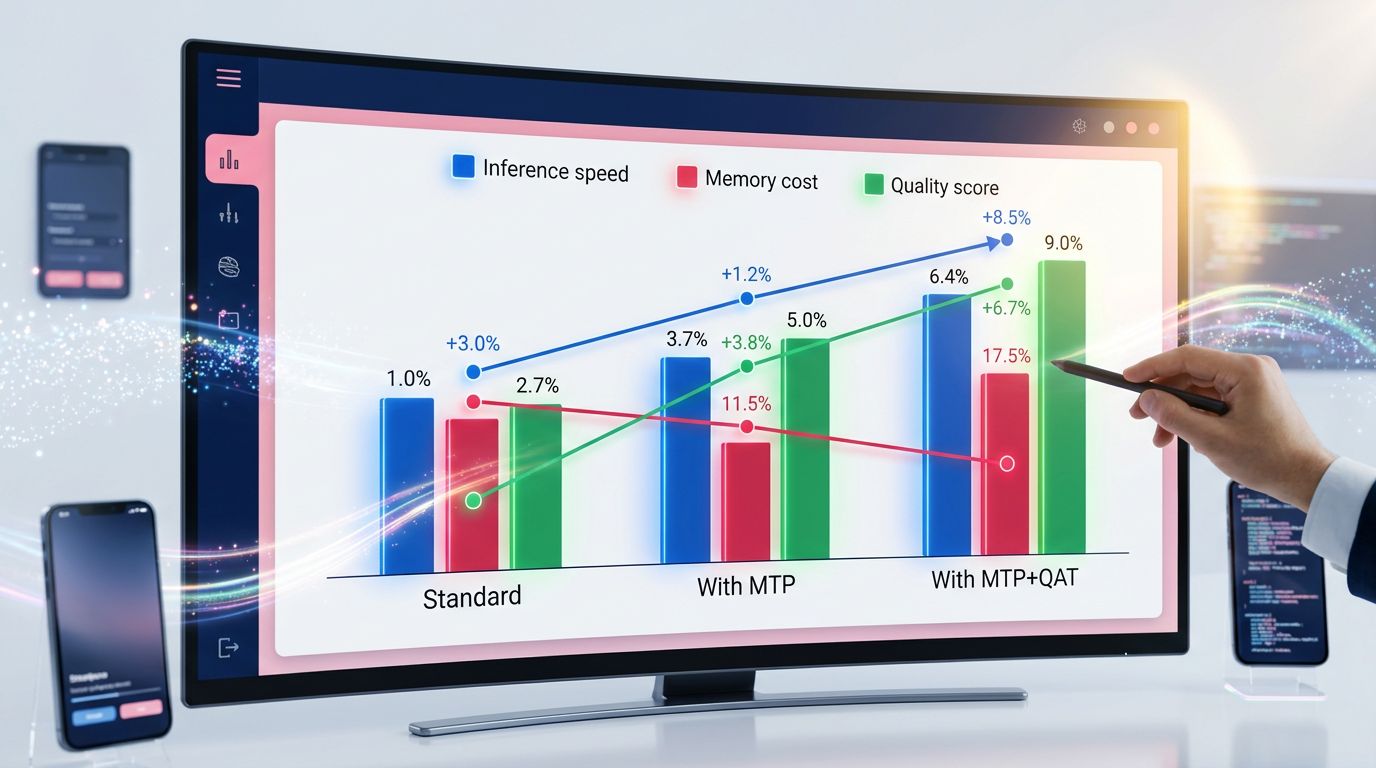
Ce qu’on ne vous dit jamais en agence : la configuration MTP + QAT permet de faire tourner un modèle 70B sur du matériel conçu pour un 13B. C’est un changement de paradigme pour les équipes qui déploient de l’IA en production avec des contraintes matérielles réelles.
Quand est-ce que ça vaut le coup de l’implémenter ?
Bonne question. Parce que MTP et QAT ne s’improvisent pas. Ce ne sont pas des options qu’on coche dans une interface — ce sont des choix d’architecture qui se font à l’entraînement.
MTP vaut le coup si :
- Vous entraînez ou fine-tunez votre propre modèle (vous avez la main sur l’architecture)
- Votre cas d’usage génère des séquences longues (résumés, rédaction, code)
- La latence d’inférence est un critère critique pour votre produit
QAT vaut le coup si :
- Vous déployez sur des infrastructures contraintes (edge computing, serveurs GPU mid-range)
- Votre budget GPU est limité et vous cherchez à maximiser le throughput
- Vous avez déjà essayé la quantification post-training et observé une dégradation inacceptable
MTP + QAT ensemble vaut le coup si :
- Vous construisez un produit IA en production avec des SLA de performance
- Vous voulez réduire vos coûts d’inférence de 60 à 75% sans refaire votre modèle de zéro
- Vous gérez des volumes importants (milliers de requêtes par heure)
Si vous utilisez des modèles via API (OpenAI, Anthropic, Mistral), ces optimisations sont déjà intégrées côté fournisseur. Vous n’avez rien à faire — mais vous n’avez pas non plus le contrôle.
Ce que ça change concrètement pour une agence ou une PME tech
Dans notre quotidien chez GDM-Pixel, on utilise des LLMs en production — pour Nova Mind, pour la génération de contenu automatisée, pour des workflows clients qui aident nos clients à automatiser leurs tâches répétitives et gagner 10 heures par semaine. La question de l’optimisation n’est pas académique. Elle impacte directement nos coûts et notre capacité à tenir des délais.
Ce qu’on voit concrètement : les modèles open source récents (DeepSeek, Llama 3, Mistral) intègrent de plus en plus ces optimisations nativement. En choisissant bien votre modèle de base, vous bénéficiez déjà d’une partie des gains sans avoir à entraîner quoi que ce soit.
Pour les équipes qui fine-tunent leurs propres modèles — et c’est une tendance qui monte chez les agences tech et les éditeurs de SaaS — intégrer QAT dès le départ est une décision qui se prend une fois et qui paie pendant toute la durée de vie du modèle.
“Optimiser après coup coûte toujours plus cher qu’optimiser dès le départ. Vrai pour le code. Vrai pour les modèles IA.”
La vraie question n’est pas “est-ce que MTP et QAT sont utiles ?” — ils le sont, les chiffres sont là. La vraie question, c’est : à quel moment de votre roadmap IA vous avez besoin de ces performances ?
Si vous êtes en phase d’expérimentation, travaillez avec des modèles quantifiés disponibles sur Hugging Face. Si vous passez en production avec des contraintes de performance, c’est le moment d’aller plus loin.
Trois points à retenir avant de vous lancer
1. MTP accélère sans sacrifier la qualité. C’est l’optimisation la plus “propre” — gains à l’inférence, représentations plus riches à l’entraînement, zéro compromis visible en production.
2. QAT résout le problème que la quantification classique crée. Si vous avez déjà rejeté la quantification à cause de la dégradation de qualité, QAT mérite un second regard. Les modèles récents entraînés avec QAT en int4 tiennent la comparaison face à leurs équivalents float16.
3. La combinaison MTP + QAT change l’équation économique du déploiement IA. Diviser par 3 le coût mémoire tout en multipliant par 3 la vitesse d’inférence, c’est la différence entre un projet IA rentable et un projet IA qui saigne du budget GPU.
Conclusion : l’optimisation IA, c’est maintenant un avantage concurrentiel
Il y a deux ans, ces techniques étaient réservées aux équipes de recherche des grands labs. Aujourd’hui, elles sont accessibles à n’importe quelle équipe technique motivée, documentées dans des papiers publics, implémentées dans des frameworks open source.
Les équipes qui les maîtrisent aujourd’hui déploient plus vite, à moindre coût, avec de meilleures performances. Les autres payent des factures GPU qui n’ont pas de raison d’être aussi élevées.
Chez GDM-Pixel, on documente ce qu’on fait réellement en production — pas ce qu’on pourrait théoriquement faire. Si vous êtes en train de construire un produit IA et que vous vous posez des questions sur votre architecture d’optimisation, notre accompagnement d’agence IA part toujours de votre stack réel — on peut le regarder ensemble et vous dire honnêtement où sont les gains les plus rapides à aller chercher.
Pas de consulting magique. Juste de l’expérience terrain sur ce qui marche.






