




Quello che nessuno vi dice sull’ottimizzazione degli LLM
Avete distribuito un modello linguistico. Funziona. Risponde. Eppure avete la sensazione di lasciare prestazioni sul tavolo — velocità di inferenza troppo lenta, costi di calcolo che salgono, qualità che raggiunge un soffitto.
Non è un problema del modello. È un problema di ottimizzazione.
Negli ultimi mesi, due tecniche stanno ricevendo un’attenzione crescente nei team di ingegneria IA: il Multi-Token Prediction (MTP) e il Quantization-Aware Training (QAT). Separatamente, ciascuna apporta guadagni misurabili. Combinate, cambiano fondamentalmente l’equazione costo/prestazioni di un deployment LLM.
Ecco quello che abbiamo osservato, le cifre reali, e come decidere se vale la pena per il vostro stack.
MTP: predire più token contemporaneamente — perché cambia tutto
Un LLM standard genera testo token per token. Un token alla volta, un passo forward alla volta. Questo è il funzionamento storico dell’architettura transformer — e anche il suo principale collo di bottiglia all’inferenza.
Il Multi-Token Prediction (MTP) rompe questa logica sequenziale. Invece di predire un singolo token successivo, il modello impara a predire più token in parallelo durante l’addestramento. In pratica, vengono aggiunte “teste di predizione” supplementari all’architettura: una testa principale per il token N+1, una seconda per N+2, una terza per N+3, ecc.
Ecco dove diventa interessante: queste teste supplementari sono attive solo durante l’addestramento. All’inferenza, il modello può utilizzare una tecnica di speculative decoding — genera più token candidati in parallelo, li verifica e convalida o rifiuta le predizioni successive in un unico passaggio.
Risultato concreto: un’accelerazione dell’inferenza da 1,5x a 3x secondo i benchmark, senza degradazione misurabile della qualità del testo generato.
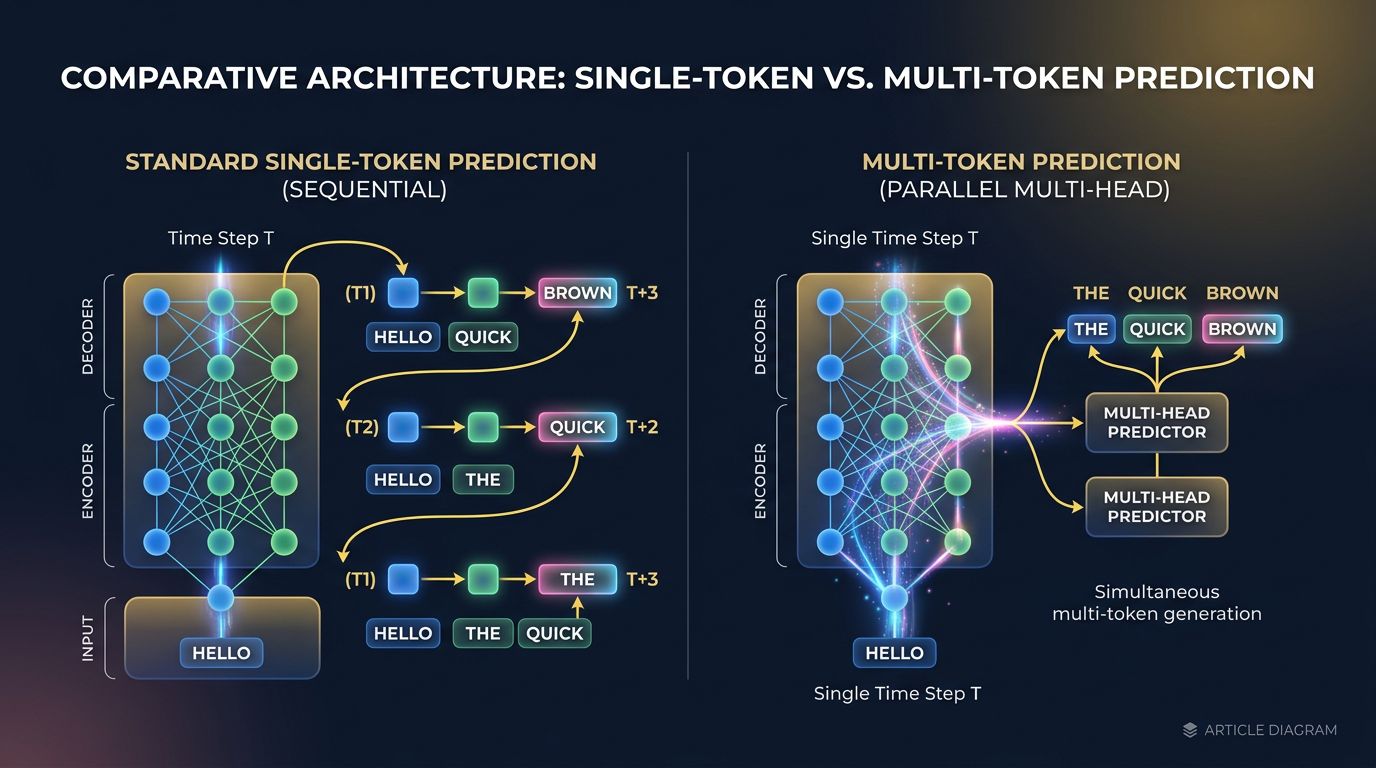
Non è teoria. DeepSeek-V3 ha integrato MTP nella sua architettura e pubblicato risultati documentati. Meta ha esplorato approcci simili nella sua ricerca su LLaMA. Il principio è validato su larga scala — ed è il tipo di ottimizzazione che sottende strumenti che utilizziamo in produzione, come Stellaris MCP per la ricerca semantica del codice.
QAT: la quantizzazione intelligente, non il solito compromesso
La quantizzazione la conoscete probabilmente. Ridurre la precisione dei pesi di un modello (da float32 a int8, int4, o anche meno) per diminuire la dimensione in memoria e accelerare i calcoli. È una tecnica diffusa, utilizzata in particolare tramite GGUF, GPTQ o AWQ.
Il problema classico: la quantizzazione post-addestramento degrada la qualità. Più si quantizza aggressivamente, più si perde in precisione sui compiti complessi. Un modello int4 post-training può perdere dal 5 al 15% di performance su certi benchmark di ragionamento.
Il QAT — Quantization-Aware Training — risolve questo problema alla radice. Invece di quantizzare a posteriori, si integra il vincolo di quantizzazione durante l’addestramento. Il modello impara a essere robusto alla precisione ridotta. Si “abitua” agli arrotondamenti e adatta i suoi pesi di conseguenza.
“La quantizzazione post-addestramento è come fotografare qualcuno senza avvisarlo. Il QAT è chiedergli di posare.”
I guadagni sono significativi. Sui benchmark pubblicati da diversi team di ricerca, un modello addestrato con QAT in int4 supera sistematicamente il suo equivalente quantizzato in post-training — a volte avvicinandosi anche alle prestazioni del modello float16 originale.
In termini pratici: si ottiene un modello 4 volte più leggero, da 2x a 3x più veloce all’inferenza, con una degradazione della qualità quasi nulla. È l’equazione che tutti cercavano.
Confrontare le tre configurazioni: le cifre grezze
Ecco cosa mostrano i benchmark recenti quando si confrontano i tre stati dello stesso modello base:
Configurazione 1 — Modello standard (senza MTP, senza QAT)
Questo è il punto di riferimento. Precisione massima, velocità di inferenza limitata dalla generazione sequenziale, alto costo di deployment (GPU A100 o H100 richiesta per modelli da 70B+). Qualità: 100% (riferimento). Velocità: 1x. Costo di memoria: 1x.
Configurazione 2 — Modello con MTP
La qualità rimane identica o leggermente superiore (l’MTP costringe il modello a sviluppare rappresentazioni più ricche durante l’addestramento). La velocità di inferenza sale a 1,8x–2,5x in base alla lunghezza delle sequenze generate. Il costo di memoria rimane simile. Questo è il guadagno più pulito: non si sacrifica nulla, si accelera.
Configurazione 3 — Modello con MTP + QAT
Qui le cifre diventano davvero interessanti. Velocità di inferenza: da 3x a 5x rispetto al modello base. Costo di memoria: diviso da 3 a 4. Qualità: 96–99% del modello originale a seconda dei compiti. Per la maggior parte dei casi d’uso reali (generazione di contenuto, classificazione, estrazione di informazioni), questa degradazione dall’1 al 4% è invisibile in produzione.
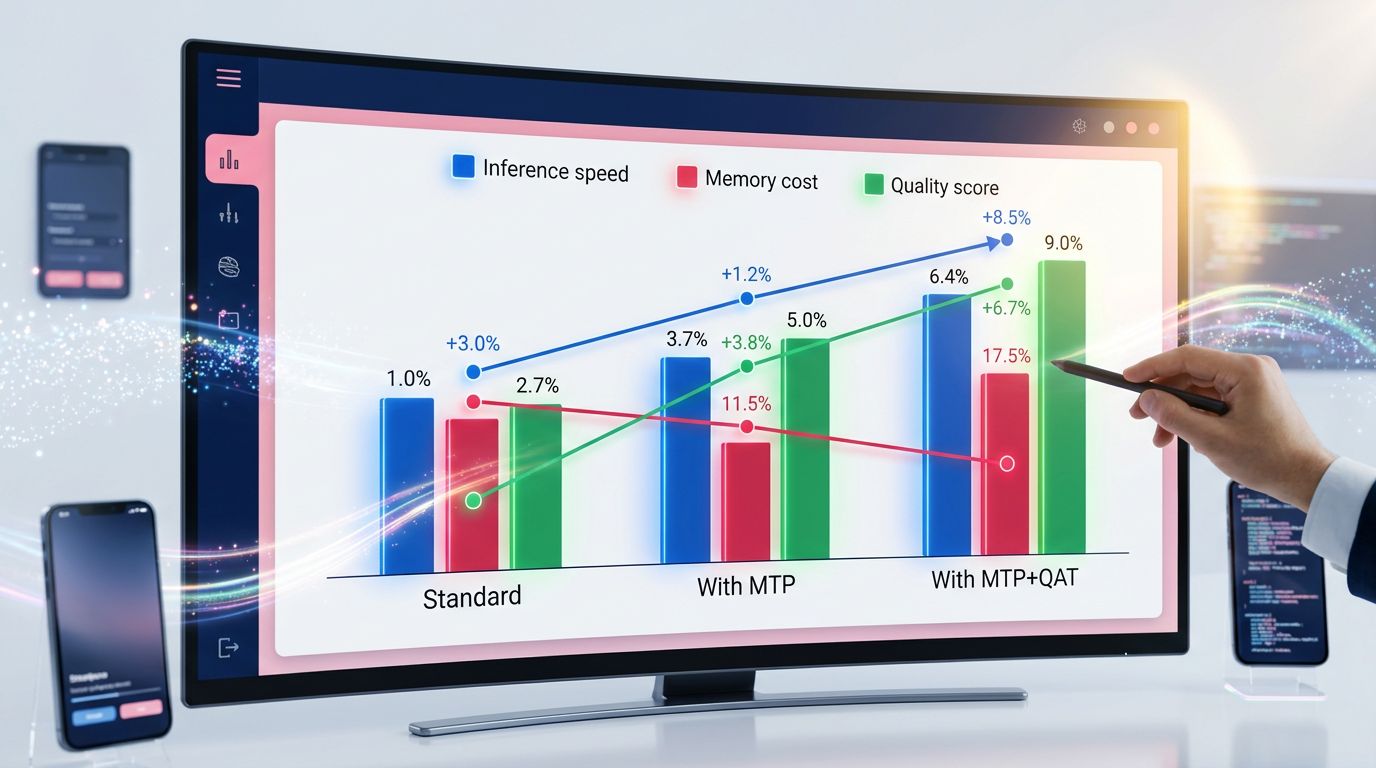
Quello che le agenzie non dicono mai: la configurazione MTP + QAT permette di far girare un modello da 70B su hardware progettato per un 13B. È un cambiamento di paradigma per i team che distribuiscono IA in produzione con reali vincoli hardware.
Quando vale la pena implementarlo?
Buona domanda. Perché MTP e QAT non si improvvisano. Non sono opzioni che si spuntano in un’interfaccia — sono scelte architetturali che si fanno durante l’addestramento.
MTP vale la pena se:
- Si addestra o si fa fine-tuning del proprio modello (si ha controllo sull’architettura)
- Il proprio caso d’uso genera sequenze lunghe (riassunti, scrittura, codice)
- La latenza di inferenza è un criterio critico per il proprio prodotto
QAT vale la pena se:
- Si distribuisce su infrastrutture con vincoli (edge computing, server GPU di fascia media)
- Il budget GPU è limitato e si cerca di massimizzare il throughput
- Si è già provata la quantizzazione post-training e si è osservata una degradazione inaccettabile
MTP + QAT insieme vale la pena se:
- Si costruisce un prodotto IA in produzione con SLA di performance
- Si vuole ridurre i costi di inferenza dal 60 al 75% senza rifare il modello da zero
- Si gestiscono volumi importanti (migliaia di richieste all’ora)
Se si utilizzano modelli tramite API (OpenAI, Anthropic, Mistral), queste ottimizzazioni sono già integrate lato fornitore. Non c’è nulla da fare — ma non si ha nemmeno il controllo.
Cosa cambia concretamente per un’agenzia o una PMI tech
Nel nostro quotidiano in GDM-Pixel, utilizziamo LLM in produzione — per Nova Mind, per la generazione automatizzata di contenuti, per workflow clienti che aiutano i nostri clienti ad automatizzare le loro attività ripetitive e guadagnare 10 ore a settimana. La questione dell’ottimizzazione non è accademica. Impatta direttamente i nostri costi e la nostra capacità di rispettare le scadenze.
Quello che vediamo concretamente: i modelli open source recenti (DeepSeek, Llama 3, Mistral) integrano sempre più queste ottimizzazioni nativamente. Scegliendo bene il modello base, si beneficia già di parte dei guadagni senza dover addestrare nulla.
Per i team che fanno fine-tuning dei propri modelli — ed è una tendenza crescente tra le agenzie tech e gli editori di SaaS — integrare QAT fin dall’inizio è una decisione che si prende una volta e che paga per tutta la vita del modello.
“Ottimizzare a posteriori costa sempre di più che ottimizzare fin dall’inizio. Vero per il codice. Vero per i modelli IA.”
La vera domanda non è “MTP e QAT sono utili?” — lo sono, le cifre sono lì. La vera domanda è: in quale momento della vostra roadmap IA avete bisogno di queste prestazioni?
Se siete in fase di sperimentazione, lavorate con modelli quantizzati disponibili su Hugging Face. Se passate in produzione con vincoli di performance, è il momento di andare oltre.
Tre punti da ricordare prima di iniziare
1. MTP accelera senza sacrificare la qualità. È l’ottimizzazione più “pulita” — guadagni all’inferenza, rappresentazioni più ricche durante l’addestramento, zero compromesso visibile in produzione.
2. QAT risolve il problema che crea la quantizzazione classica. Se avete già rifiutato la quantizzazione a causa della degradazione della qualità, QAT merita un secondo sguardo. I modelli recenti addestrati con QAT in int4 reggono il confronto con i loro equivalenti float16.
3. La combinazione MTP + QAT cambia l’equazione economica del deployment IA. Dividere il costo di memoria per 3 mentre si moltiplica la velocità di inferenza per 3 è la differenza tra un progetto IA redditizio e uno che dissangua il budget GPU.
Conclusione: l’ottimizzazione IA è ora un vantaggio competitivo
Due anni fa, queste tecniche erano riservate ai team di ricerca dei grandi laboratori. Oggi sono accessibili a qualsiasi team tecnico motivato, documentate in paper pubblici, implementate in framework open source.
I team che le padroneggiano oggi distribuiscono più velocemente, a costo inferiore, con prestazioni migliori. Gli altri pagano bollette GPU che non hanno ragione di essere così alte.
In GDM-Pixel, documentiamo quello che facciamo davvero in produzione — non quello che potremmo teoricamente fare. Se state costruendo un prodotto IA e avete domande sulla vostra architettura di ottimizzazione, il nostro supporto di agenzia IA parte sempre dal vostro stack reale — possiamo esaminarlo insieme e dirvi onestamente dove si trovano i guadagni più rapidi da ottenere.
Nessuna consulenza magica. Solo esperienza sul campo su ciò che funziona davvero.






